Deep Learning and Neural Networks
Last updated on 2026-07-06 | Edit this page
Overview
Questions
- What is an artificial neural network?
- What does “deep” mean in deep learning?
- How do neural networks learn from errors?
- Why does deep learning require substantial data and computing resources?
Objectives
- Describe what an artificial neural network is using an analogy.
- Explain what “deep” means in deep learning.
- Identify types of tasks that deep learning excels at.
- Understand why deep learning requires a lot of data and computing power.
What is a Neural Network?
Deep learning is built on a concept called the artificial neural network.
The name comes from a loose analogy with biology. In the human brain, neurons receive signals from other neurons. If the combined incoming signal is strong enough, the neuron “fires” and passes a signal onwards.
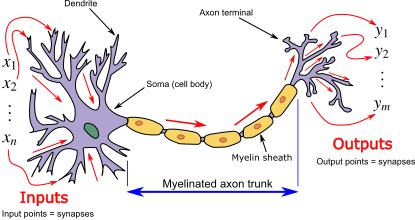
An artificial neuron works in a simplified mathematical way:
- It receives numbers as inputs.
- Each input is multiplied by a weight, which represents its importance.
- These weighted values are added together.
- If the result is large enough, the neuron produces an output.
- That output is then sent to the next layer.
Both biological and artificial neurons act as filters that combine many incoming signals, weighted by importance, and decide whether the combined signal should be passed to the next layer and, if so, how strongly the it should be passed on.
A single artificial neuron is rarely useful on its own. But, if you arrange many neurons together, you get a layer, and if you stack multiple layers you get a neural network. It is the depth of the layer stacking that gives deep learning its name and its power.
Layers and Depth
A neural network is typically organised into three types of layers:
- An input layer, which receives the raw data.
- One or more hidden layers, where most of the computation happens.
- An output layer, which produces the final prediction.

As data passes through the network, each layer transforms it into a slightly more abstract representation.
For example, in image recognition:
- An early layer might detect simple edges and lines.
- A later layer might detect shapes or textures.
- A deeper layer might detect complex structures such as faces.
In text processing:
- Early layers might detect characters or short word patterns.
- Middle layers might represent words or phrases.
- Later layers might capture aspects of meaning or context.
This hierarchical pattern detection is one of the main strengths of deep learning.
The word deep simply refers to the number of hidden layers. A shallow model might have one hidden layer. A deep model may have dozens or even hundreds of layers.
Types of Neural Network
There are many neural network architectures, each suited to particular tasks. Just a few common examples are discussed below.
Convolutional Neural Networks (CNNs)
CNNs are particularly effective for image and video analysis. They use specialised layers that focus on local patterns, such as edges and textures. Image classification tools are built on this type of architecture.
Some examples of CNNs being used for image analysis in research include:
- Analysing satellite imagery to detect environmental change.
- Identifying cell structures in microscopy images.
- Digitising and classifying historical documents.
- Transcribing and analysing handwritten documents
Recurrent Neural Networks (RNNs)
RNNs were designed to handle sequential data, such as time-series measurements or text. They process information step by step, maintaining a form of internal memory. In many applications, they have now been replaced by more advanced architectures.
Transformers
Transformers are the foundation of most modern natural language processing systems. They are especially effective at modelling relationships within sequences of text and form the basis of contemporary large language models, which we will examine in the next episode.
To read more about different neural network architectures have a look at the Neural Network Zoo, a cheat sheet for neural network architectures.
Training a Neural Network
During training, a neural network follows a repeated cycle.
- The network receives an input and produces a prediction.
- The prediction is compared with the correct answer.
- The difference between them is calculated as an error.
- This error signal is sent backwards through the network (known as backpropagation).
- The weights are adjusted slightly to reduce future errors.
This process is repeated across many times and on many examples, often millions.
Try Training a Neural Network
You can experiment with the process of training a neural network interactively using tools such as Tensorflow Playground.
The main task in TensorFlow Playground is classification: the network is trying to learn to separate two groups of data points (shown as orange and blue dots) by finding a boundary between them.
What the colours mean
The data points (the small circles on the graph) are coloured orange or blue to show which group they belong to.
The background colour of the output panel shows what the network is currently predicting for every possible point on the graph. If an area is blue, the network would classify any point there as belonging to the blue group. If it is orange, it would classify it as orange. The deeper and more saturated the colour, the more confident the network is in that prediction.
As training progresses, watch how the background pattern shifts and sharpens. This is the network adjusting its internal weights and gradually learning a better boundary between the two groups.
The lines connecting neurons in the hidden layers show the weights of the connections between neurons. A blue line means the connection has a positive weight and so the signal is passed forward and amplified. An orange line means the connection has a negative weight and so the signal is inverted or suppressed. Thick lines indicate strong weights in either direction whereas thin lines indicate weak ones.
What to try
- Press the play button and watch the network train. Notice how the background pattern in the output panel gradually changes as the network improves. The epoch counter shows how many times the network has passed through the training data.
- Try using a dataset with more complex boundaries - does increasing the number of features, hidden layers and/or neurons allow the neural network to learn more complex boundaries?
How can I Train My Own Deep Learning Model?
Training a deep learning model from scratch is significantly more demanding than training a conventional machine learning model, but it is not out of reach for motivated researchers, particularly with access to institutional computing infrastructure and Research Software Engineering support. More commonly, researchers work with pre-trained models and adapt them, rather than training from scratch.
What skills this requires
Deep learning requires all of the skills needed for conventional machine learning (programming in Python, data preparation, evaluation) plus additional capabilities. You will need familiarity with a deep learning framework such as PyTorch or TensorFlow, both of which have extensive documentation and active research communities.
Access to appropriate hardware is a practical requirement. Modern neural networks use very large datasets, contain millions of adjustable parameters, and iterate thousands of time. Therefore, training deep learning models on a standard laptop CPU is rarely feasible for research-scale tasks. Most researchers use GPUs, either through institutional high-performance computing (HPC) facilities or cloud platforms such as Google Colab, which provides free GPU access for smaller experiments.
Experiment management becomes important at this level of complexity. Tracking which model configuration produced which results, managing large datasets, and handling training runs that may take hours or days requires a great deal of organisation and tools such as Weights & Biases or MLflow.
Deep learning also demands a somewhat deeper understanding of model architecture and training dynamics than conventional ML. You need enough conceptual understanding to diagnose when training is going wrong, for example, when a model is failing to learn, overfitting, or producing unexpected outputs.
Choosing the Right Machine Learning or Deep Learning Model: Interpretable Models vs Black Box Models
Before choosing a machine learning approach, one of the most important questions to ask is:
“Do I need to understand why the model makes a particular prediction, or is the prediction itself sufficient?”
This is the distinction between interpretable and black box models.
An interpretable model produces outputs that can be traced back to a clear, human-readable explanation. A linear regression, for instance, gives you a coefficient for each input variable and you can see directly how much each factor contributed to the prediction. A decision tree reaches its conclusion through a series of simple yes/no rules that can be printed out and inspected. When your research requires accountability, transparency, or regulatory compliance, interpretability may be essential.
A black box model, such as a deep neural network with many layers, may produce highly accurate predictions, but the internal reasoning process is not directly accessible. You can observe the inputs and outputs, but the path between them involves thousands or millions of interacting numerical parameters that do not correspond to human-understandable concepts.

Consider an interpretable model when:
- You need to explain or justify individual predictions
- Your field has regulatory or ethical requirements for transparency
- Discovering which variables matter is part of the research question
- Stakeholders (e.g. patients, policymakers, or funders) need to understand the rationale
A black box model may be acceptable when:
- Predictive accuracy is the primary goal
- Outputs will be validated independently before acting on them
- Large volumes of complex data (images, audio) make interpretability impractical
- Artificial neural networks consist of layers of weighted computational units inspired by biological neurons.
- ‘Deep’ refers to having multiple hidden layers that learn increasingly abstract representations.
- Training involves making predictions, measuring error, and adjusting weights using backpropagation.
- Deep learning excels at complex pattern recognition tasks such as image, audio, and text analysis.
- Large models require extensive data and computing resources to train effectively.