What is Artificial Intelligence?
Last updated on 2026-07-06 | Edit this page
Estimated time: 20 minutes
Overview
Questions
- What is AI?
- What are some categories of AI?
- Which factors have contributed to the AI boom over the last few years?
Objectives
- Give a working definition of Artificial Intelligence.
- Explain a test for machine intelligence.
- Describe how AI, machine learning, deep learning, and LLMs relate to each other using a nested diagram.
Defining AI
Artificial Intelligence, or AI, is a broad term. A useful working definition is:
AI refers to computer systems that perform tasks which would typically require human intelligence.
These tasks might include recognising images, understanding language, making recommendations, detecting patterns in data, or playing strategic games.
Noticing AI
Think of a recent example of an AI system you have used or encountered.
Briefly describe:
- the task it was performing
- the information it received as input
- the output it generated.
Examples might include:
- A generative AI tool like ChatGPT, Microsoft Copilot or Claude to edit your writing.
- A code assistant like GitHub Copilot improving your research code.
- A spam filter classifying incoming emails as “spam” or “not spam”.
- A video streaming platform suggesting films based on previous watching behaviour.
- Autocomplete predicting the next word or line of code while you type.
- A medical imaging tool highlighting areas of a scan that may require clinical attention.
In each case, the system is performing a specific task based on patterns learned from data.
It is worth noting that AI is not a single technique or tool. It is an umbrella term covering a wide range of approaches developed over several decades.
A Brief History of AI in Three Phases
Rule-based systems (1950s–1980s) Early AI systems relied on explicit rules written by humans. For example, a medical expert system might contain hundreds of “if–then” statements created by specialists, designed to lead to a diagnosis. These systems could perform well in narrow domains but were inflexible and difficult to scale. For example, a chatbot called ELIZA was developed in 1966, it answered questions only according to explicitly defined rules.
Statistical approaches (1980s–2000s) Researchers began using probability and statistics to handle uncertainty and variability in real-world data. Instead of hard-coded rules, systems estimated likelihoods and made predictions based on data.
Modern machine learning (2000s–present) With increased data and computing power, systems began to “learn” patterns directly from large datasets. Rather than being told exactly what to do, they infer patterns from examples.
How do we assess artificial intelligence?
Throughout all these phases, the goal has remained broadly the same: to build systems that can carry out tasks we associate with intelligent behaviour.
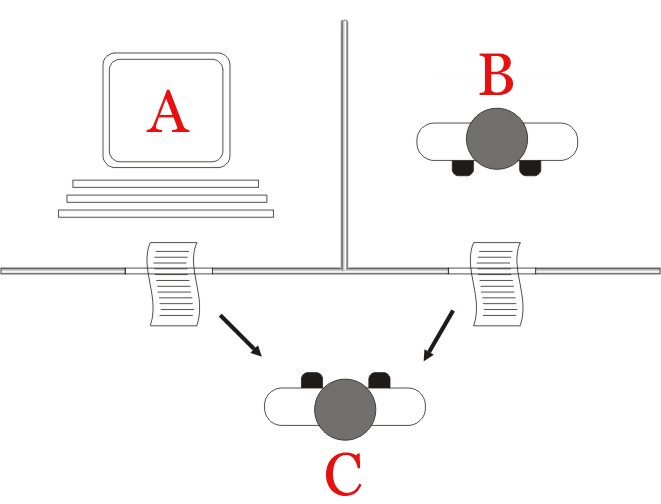
In 1950 Alan Turing proposed a test for machine intelligence, known as the Turing Test:
“The idea of the test is that the machine has to try and pretend to be a man, by answering questions put to it, and it will only pass if the pretence is reasonably convincing. A considerable portion of a jury, who should not be experts about machines, must be taken in by the pretence”
So, this test involves a human judge engaging in natural language conversations with both a human and a machine designed to generate human-like responses. The machine passes the test if it can convince the judge that it is human a significant fraction of the time.
A 2026 article in PNAS reports the performance of AI systems including ELIZA and GPT-4.5 in two randomised, controlled, and pre-registered Turing tests. Participants had 5 minute conversations simultaneously with another human participant and one of these systems before judging which conversational partner they thought was human. When prompted to adopt a human-like persona, LLaMa-3.1 was judged to be the human 56% of the time and GPT-4.5 was judged to be the human 73% of the time, significantly more often than the real human participant was selected. In contrast, ELIZA was judged to be the human only 23% of the time(Jones & Bergen, 2026).
This result illustrates how capable current systems have become at specific tasks (i.e. having a human-like conversation). However, passing a five-minute conversation test is not the same as general intelligence. GPT-4.5 has been trained on an enormous quantity of human-written text, which makes it exceptionally good at producing human-like language and this is exactly what the Turing test measures. It is, in a sense, the task it was most directly prepared for.
It’s important that we also consider what the same system cannot do. It cannot walk into an unfamiliar laboratory and figure out how the equipment works. It cannot notice that a colleague seems stressed and decide whether to ask about it. It cannot read a paper, recognise that the methodology is flawed, and devise a better approach. These are things a competent human researcher does routinely, involving transferring knowledge and judgement flexibly across situations they have never seen before. No current AI system has of the components we would associate with human intelligence.
The AI Family Tree
AI can be visualised as a set of nested fields. Each inner layer represents a more specific set of techniques within the broader area.
┌─────────────────────────────────────────┐
│ Artificial Intelligence │
│ ┌───────────────────────────────────┐ │
│ │ Machine Learning │ │
│ │ ┌─────────────────────────────┐ │ │
│ │ │ Deep Learning │ │ │
│ │ │ ┌───────────────────────┐ │ │ │
│ │ │ │ LLMs (e.g. GPT, etc) │ │ │ │
│ │ │ └───────────────────────┘ │ │ │
│ │ └─────────────────────────────┘ │ │
│ └───────────────────────────────────┘ │
└─────────────────────────────────────────┘We can interpret this diagram from the outside in:
- Artificial Intelligence is the broadest category. It includes any computational method aimed at performing tasks associated with intelligence.
- Machine Learning is a subset of AI focused on systems that learn patterns from data rather than relying purely on hand-written rules.
- Deep Learning is a subset of machine learning that uses multi-layered neural networks to model complex patterns.
- Large Language Models (LLMs) are a specific application of deep learning, trained on vast amounts of text data to generate and understand language.
As the course progresses, we will move gradually from the outer layer towards the inner layers, building conceptual understanding at each step.
Why AI Now?
AI research has existed for decades, so why has it become so prominent recently?
Three enabling factors have converged:
Data availability: The growth of the internet, digital services, sensors, and large-scale data collection has created vast datasets for training models.
Computing power: Graphics Processing Units (GPUs), originally developed for rendering images in gaming, turned out to be highly effective for the kinds of parallel computations used in deep learning.
Algorithmic advances: New training methods and model architectures have significantly improved performance, particularly in areas such as image recognition and natural language processing. For example the transformer architecture that underpins most large language models (transformer is the ‘T’ in ChatGPT)
The current wave of AI is therefore not the result of a single breakthrough, but the interaction between data, hardware, and improved methods.
- Artificial Intelligence is a broad field concerned with systems that perform tasks associated with human intelligence.
- Machine learning is a subset of AI that learns from data.
- Deep learning is a subset of machine learning based on multi-layered neural networks.
- Large language models are a specific type of deep learning model focused on language.
- The recent growth of AI has been driven by data availability, increased computing power, and algorithmic advances.
References
- Jones, C. R., & Bergen, B. K. (2026). Large language models pass a standard three-party Turing test. Proceedings of the National Academy of Sciences, 123(21), e2524472123.
- Toosi, A., Bottino, A. G., Saboury, B., Siegel, E., & Rahmim, A. (2021). A brief history of AI: how to prevent another winter (a critical review). PET clinics, 16(4), 449-469.
- French, R. M. (2000). The Turing Test: the first 50 years. Trends in cognitive sciences, 4(3), 115-122.