All in One View
Content from Learning Objectives
Last updated on 2026-06-30 | Edit this page
Estimated time: 12 minutes
Overview
Questions
Objectives
- Describe the AI landscape and how key terms (AI, machine learning, deep learning, LLMs) relate to one another.
- Explain in plain language how machine learning models learn from data.
- Describe what a neural network is and why “deep” learning is powerful.
- Explain how large language models (LLMs) work at a conceptual level.
- Critically evaluate claims about AI capabilities and limitations in a research context.
- Identify potential use cases and ethical considerations for AI in their own research.
Content from What is Artificial Intelligence?
Last updated on 2026-07-06 | Edit this page
Estimated time: 20 minutes
Overview
Questions
- What is AI?
- What are some categories of AI?
- Which factors have contributed to the AI boom over the last few years?
Objectives
- Give a working definition of Artificial Intelligence.
- Explain a test for machine intelligence.
- Describe how AI, machine learning, deep learning, and LLMs relate to each other using a nested diagram.
Defining AI
Artificial Intelligence, or AI, is a broad term. A useful working definition is:
AI refers to computer systems that perform tasks which would typically require human intelligence.
These tasks might include recognising images, understanding language, making recommendations, detecting patterns in data, or playing strategic games.
Noticing AI
Think of a recent example of an AI system you have used or encountered.
Briefly describe:
- the task it was performing
- the information it received as input
- the output it generated.
Examples might include:
- A generative AI tool like ChatGPT, Microsoft Copilot or Claude to edit your writing.
- A code assistant like GitHub Copilot improving your research code.
- A spam filter classifying incoming emails as “spam” or “not spam”.
- A video streaming platform suggesting films based on previous watching behaviour.
- Autocomplete predicting the next word or line of code while you type.
- A medical imaging tool highlighting areas of a scan that may require clinical attention.
In each case, the system is performing a specific task based on patterns learned from data.
It is worth noting that AI is not a single technique or tool. It is an umbrella term covering a wide range of approaches developed over several decades.
A Brief History of AI in Three Phases
Rule-based systems (1950s–1980s) Early AI systems relied on explicit rules written by humans. For example, a medical expert system might contain hundreds of “if–then” statements created by specialists, designed to lead to a diagnosis. These systems could perform well in narrow domains but were inflexible and difficult to scale. For example, a chatbot called ELIZA was developed in 1966, it answered questions only according to explicitly defined rules.
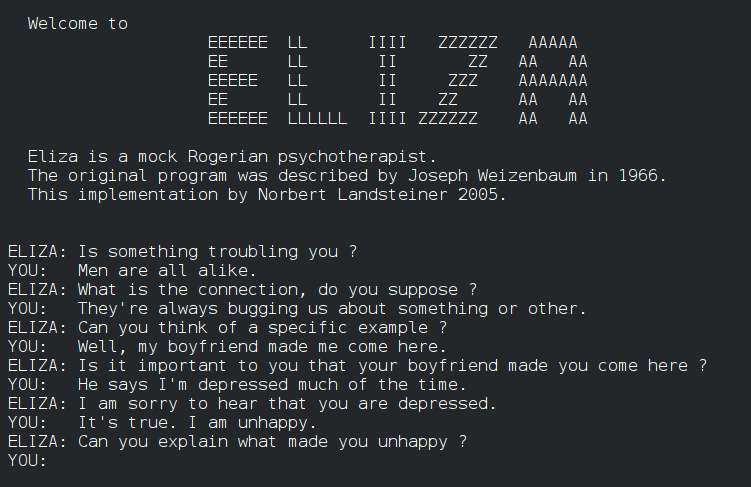
Statistical approaches (1980s–2000s) Researchers began using probability and statistics to handle uncertainty and variability in real-world data. Instead of hard-coded rules, systems estimated likelihoods and made predictions based on data.
Modern machine learning (2000s–present) With increased data and computing power, systems began to “learn” patterns directly from large datasets. Rather than being told exactly what to do, they infer patterns from examples.
How do we assess artificial intelligence?
Throughout all these phases, the goal has remained broadly the same: to build systems that can carry out tasks we associate with intelligent behaviour.
In 1950 Alan Turing proposed a test for machine intelligence, known as the Turing Test:
“The idea of the test is that the machine has to try and pretend to be a man, by answering questions put to it, and it will only pass if the pretence is reasonably convincing. A considerable portion of a jury, who should not be experts about machines, must be taken in by the pretence”
So, this test involves a human judge engaging in natural language conversations with both a human and a machine designed to generate human-like responses. The machine passes the test if it can convince the judge that it is human a significant fraction of the time.
A 2026 article in PNAS reports the performance of AI systems including ELIZA and GPT-4.5 in two randomised, controlled, and pre-registered Turing tests. Participants had 5 minute conversations simultaneously with another human participant and one of these systems before judging which conversational partner they thought was human. When prompted to adopt a human-like persona, LLaMa-3.1 was judged to be the human 56% of the time and GPT-4.5 was judged to be the human 73% of the time, significantly more often than the real human participant was selected. In contrast, ELIZA was judged to be the human only 23% of the time(Jones & Bergen, 2026).
This result illustrates how capable current systems have become at specific tasks (i.e. having a human-like conversation). However, passing a five-minute conversation test is not the same as general intelligence. GPT-4.5 has been trained on an enormous quantity of human-written text, which makes it exceptionally good at producing human-like language and this is exactly what the Turing test measures. It is, in a sense, the task it was most directly prepared for.
It’s important that we also consider what the same system cannot do. It cannot walk into an unfamiliar laboratory and figure out how the equipment works. It cannot notice that a colleague seems stressed and decide whether to ask about it. It cannot read a paper, recognise that the methodology is flawed, and devise a better approach. These are things a competent human researcher does routinely, involving transferring knowledge and judgement flexibly across situations they have never seen before. No current AI system has of the components we would associate with human intelligence.
The AI Family Tree
AI can be visualised as a set of nested fields. Each inner layer represents a more specific set of techniques within the broader area.
┌─────────────────────────────────────────┐
│ Artificial Intelligence │
│ ┌───────────────────────────────────┐ │
│ │ Machine Learning │ │
│ │ ┌─────────────────────────────┐ │ │
│ │ │ Deep Learning │ │ │
│ │ │ ┌───────────────────────┐ │ │ │
│ │ │ │ LLMs (e.g. GPT, etc) │ │ │ │
│ │ │ └───────────────────────┘ │ │ │
│ │ └─────────────────────────────┘ │ │
│ └───────────────────────────────────┘ │
└─────────────────────────────────────────┘We can interpret this diagram from the outside in:
- Artificial Intelligence is the broadest category. It includes any computational method aimed at performing tasks associated with intelligence.
- Machine Learning is a subset of AI focused on systems that learn patterns from data rather than relying purely on hand-written rules.
- Deep Learning is a subset of machine learning that uses multi-layered neural networks to model complex patterns.
- Large Language Models (LLMs) are a specific application of deep learning, trained on vast amounts of text data to generate and understand language.
As the course progresses, we will move gradually from the outer layer towards the inner layers, building conceptual understanding at each step.
Why AI Now?
AI research has existed for decades, so why has it become so prominent recently?
Three enabling factors have converged:
Data availability: The growth of the internet, digital services, sensors, and large-scale data collection has created vast datasets for training models.
Computing power: Graphics Processing Units (GPUs), originally developed for rendering images in gaming, turned out to be highly effective for the kinds of parallel computations used in deep learning.
Algorithmic advances: New training methods and model architectures have significantly improved performance, particularly in areas such as image recognition and natural language processing. For example the transformer architecture that underpins most large language models (transformer is the ‘T’ in ChatGPT)
The current wave of AI is therefore not the result of a single breakthrough, but the interaction between data, hardware, and improved methods.
- Artificial Intelligence is a broad field concerned with systems that perform tasks associated with human intelligence.
- Machine learning is a subset of AI that learns from data.
- Deep learning is a subset of machine learning based on multi-layered neural networks.
- Large language models are a specific type of deep learning model focused on language.
- The recent growth of AI has been driven by data availability, increased computing power, and algorithmic advances.
References
- Jones, C. R., & Bergen, B. K. (2026). Large language models pass a standard three-party Turing test. Proceedings of the National Academy of Sciences, 123(21), e2524472123.
- Toosi, A., Bottino, A. G., Saboury, B., Siegel, E., & Rahmim, A. (2021). A brief history of AI: how to prevent another winter (a critical review). PET clinics, 16(4), 449-469.
- French, R. M. (2000). The Turing Test: the first 50 years. Trends in cognitive sciences, 4(3), 115-122.
Content from Machine Learning - Teaching Computers from Data
Last updated on 2026-07-06 | Edit this page
Estimated time: 45 minutes
Overview
Questions
- How is machine learning different from traditional programming?
- What are supervised, unsupervised, and reinforcement learning?
- What does it mean to train and test a model?
- What is overfitting, and why does it matter?
- When is machine learning the right choice and when is it not?
Objectives
- Explain what machine learning is and how it differs from traditional programming.
- Distinguish between supervised, unsupervised, and reinforcement learning.
- Describe the concept of training, testing, and overfitting in plain language.
- Explain the difference between interpretable and black box models, and why it matters.
- Recognise when a traditional statistical approach may be more appropriate than machine learning.
From Rules to Learning
In traditional programming, a human writes explicit rules for some data,the computer follows them and provides some output.
For example, a researcher studying whether a scientific paper is relevant to a systematic review on arthritis interventions might write rules such as:
- If the paper mentions “randomised controlled trial” and the “arthritis”, include it.
- If the paper is published before 1990, exclude it.
The computer applies those rules to some data, in this case, paper abstracts, and the output is fully determined by the rules written in advance.
The logic flows like this:
Rules + Data -> Output
This works reasonably well when the criteria are clear and consistent. However, in reality, relevance is rarely so clean. Papers use different terminology, describe similar interventions in different ways, and sometimes the abstract alone is not enough to judge. Writing rules that handle all of this becomes increasingly difficult and fragile.
Machine learning takes a different approach. Instead of writing detailed rules, we provide:
- Data - a large collection of abstracts
- The desired outputs for a subset of the data - human judgements about whether papers are relevant
The system then learns the patterns that connect the two.
The logic becomes:
Data + Output -> Rules
In other words, the computer infers the rules for itself.
Machine Learning Analogy
A useful analogy is teaching a child to recognise dogs. You would not provide a formal definition involving ear angles and tail length. Instead, you would show many examples of dogs and non-dogs. Over time, the child internalises patterns that allow them to identify new dogs correctly.
Machine learning systems operate in a similar way. They detect statistical patterns in examples and use those patterns to make predictions about new data.

Three Types of Machine Learning
Machine learning is not one single method. It includes several different learning paradigms.
| Type | What the model has | What it learns to do | Example |
|---|---|---|---|
| Supervised Learning | Labelled examples (input + correct answer) | Map inputs to correct outputs | Email spam detection, disease classification |
| Unsupervised Learning | Unlabelled data only | Find hidden patterns or groups | Customer segmentation, topic modelling of papers |
| Reinforcement Learning | Reward signals from environment | Maximise a reward through trial and error | Game-playing AI, robot control |
Supervised learning
In supervised learning, each example includes both the input and the correct output.
For instance, a dataset of medical images might include thousands of scans labelled “tumour” or “no tumour”. The system learns to map image features to the correct diagnosis.
This is currently the most widely used type of machine learning in research and industry.
Unsupervised learning
In unsupervised learning, the system is given data without explicit labels. Its task is to find structure within the data.
For example, given a large collection of research paper abstracts, an unsupervised model might group them into themes based on patterns of word usage. No one tells the system what the topics are in advance.
This approach is useful for exploration and discovery.
Reinforcement learning
In reinforcement learning, an agent interacts with an environment and receives feedback in the form of rewards or penalties.
Over time, the system learns which actions maximise long-term reward. This approach has been used in game-playing systems and robotics.
Machine Learning in Research Scenarios
Match each scenario to supervised, unsupervised, or reinforcement learning:
- A tool that groups research papers into topics automatically, without anyone labelling the topics in advance.
- A system trained on thousands of labelled X-rays to flag potential tumours.
- A robot that learns to navigate a maze by receiving a reward signal each time it gets closer to the exit.
1 = Unsupervised learning 2 = Supervised learning 3 = Reinforcement learning
What Kind of Task Is It?
Machine learning can be applied to several different types of tasks: regression, classification, clustering and dimensionality reduction. Supervised learning is usually applied to regression and classification tasks, whereas unsupervised learning is often applied to clustering or dimensionality reduction tasks (although there are exceptions to both of these statements).
Regression — predicting a continuous numerical value. For example, predicting a patient’s length of hospital stay based on clinical variables, or estimating the yield of a crop from environmental measurements. The output is a number on a continuous scale.
Classification — predicting which category an input belongs to. For example, classifying an email as spam or not spam, identifying the species of a plant from an image, or flagging whether a research paper is relevant to a systematic review. The output is a label chosen from a defined set.
Clustering — grouping unlabelled data into meaningful clusters based on similarity, without being told in advance what the groups are. For example, grouping survey respondents by response patterns, or identifying subtypes of a disease from patient data.
Dimensionality reduction - compressing high-dimensional data into a simpler representation for visualisation or further analysis. For example, in gene expression research, scientists might compress thousands of gene measurements per patient down to two or three variables that capture the most meaningful variation, making it possible to plot all patients on a single chart and spot groupings that may correspond to clinically relevant subtypes.
When choosing the right machine learning algorithm for the job, often deciding which task is required is the first step. For a guide, have a look at the scikit-learn algorithm cheat sheet
How a Model Learns
Let’s walk through a simplified example of supervised learning:
- Start with a dataset of examples. For example, 10,000 labelled medical images.
- Split the data into two parts:
- A training set
- A test set
The training set is used to teach the model. The test set is kept separate and used only for evaluation.
This split matters because we want to know whether the model performs well on new, unseen data. If we test it on the same data it has already seen, we learn very little about its real-world usefulness.
- During training, the model adjusts its internal parameters. You can think of these as thousands or millions of adjustable dials. The system tweaks these settings to reduce the number of mistakes it makes on the training data.
- After training, we evaluate the model on the test set. This tells us how well it generalises beyond the examples it was shown during learning.
Image Classification with the Teachable Machine
A useful way to build understanding without the need to write code is to experiment with tools such as Teachable Machine which allow you to train a simple image or sound classifier using your own examples, without any coding required.
“Teachable Machine is a web-based tool that makes creating machine learning models fast, easy, and accessible to everyone. You train a computer to recognize your images, sounds, and poses without writing any machine learning code.”
Find two different objects and have a go training an image classifying machine learning model.
Notice how the quality and quantity of training examples strongly influence the behaviour of the model.
For more information about the Teachable Machine, have a look through the FAQs on their website: https://teachablemachine.withgoogle.com/faq
When Not to Use Machine Learning
Machine learning is a powerful set of tools, but it is not always the right one. Depending on the research question, traditional statistics may be better suited.
The main factor that should help you decide whether your goal is explanation or prediction:
- Explanation involves understanding the relationship between variables, testing hypotheses, and drawing causal or inferential conclusions e.g. Does this treatment reduce recovery time?
- Prediction involves building a system that produces accurate outputs for new cases e.g. Can we flag likely hospital readmissions before they happen?
Traditional statistical methods including regression models, t-tests, and ANOVA have been developed with explanation as their primary goal. They come with well-understood assumptions and and inferential frameworks, such as p-values and confidence intervals, that are widely understood in research communities. When your goal is to understand what is going on and why, these tools are often more appropriate than a machine learning model.
Machine learning, by contrast, is optimised for predictive performance. It works well when the dataset is large, the relationship between inputs and outputs is complex, the goal is prediction rather than inference, and formal hypothesis testing is not required.
Many research workflows combine a statistical model to test a hypothesis, and then a machine learning model to build a practical prediction tool. The important thing is to choose machine learning or traditional statistics deliberately, based on your research question.
How Can I Train My Own Machine Learning Model?
For many research tasks, training a machine learning model from scratch can be useful and within the realm of possibility. Researchers do this regularly, not because off-the-shelf tools are unavailable, but because a custom model trained on domain-specific data can outperform a general-purpose one, and because owning the model gives you full control over how it is evaluated, documented, and reported.
What skills this requires
Training a conventional machine learning model requires programming skills, typically in Python or R, and familiarity with standard machine learning libraries such as scikit-learn (Python) or randomForest/xgboost/tidymodels (R).
A basic understanding of data preparation is essential as most of the practical work in machine learning involves cleaning, transforming, and structuring data rather than tuning models.
An understanding of statistics is also valuable. Understanding what your evaluation metrics actually mean, and being able to reason about whether your model has learned something meaningful or has simply exploited a pattern in the training data, requires a degree of statstical understanding.
If you are new to programming or data science, many researchers begin with the Carpentries lessons on Plotting and Programming in Python or R for Reproducible Scientific Analysis, followed by Introduction to Machine Learning with Python or Machine Learning for Tabular Data in R.
Working with a Research Software Engineer
If the machine learning component is central to your research, working with a Research Software Engineer (RSE) could be a helpful. RSEs can help you choose appropriate methods, implement them correctly and efficiently, and ensure your code is reliable, robust and well-documented.
- Machine learning systems learn patterns from data rather than following rules.
- Training and test sets help us assess whether a model generalises to new data.
- Interpretable models make their reasoning transparent whereas black box models do not.
- Traditional statistical methods are often more appropriate than machine learning when the goal is explanation rather than prediction, particularly with small datasets.
- The quality and representativeness of training data strongly influence model performance and fairness.
References
- scikit-learn algorithm cheat sheet
- Van De Schoot, R., De Bruin, J., Schram, R., Zahedi, P., De Boer, J., Weijdema, F., … & Oberski, D. L. (2021). An open source machine learning framework for efficient and transparent systematic reviews. Nature machine intelligence, 3(2), 125-133.
- Teachable Machine
- geeksforgeeks Introduction to Machine Learning
- Overfitting in Machine Learning
Content from Deep Learning and Neural Networks
Last updated on 2026-07-06 | Edit this page
Estimated time: 40 minutes
Overview
Questions
- What is an artificial neural network?
- What does “deep” mean in deep learning?
- How do neural networks learn from errors?
- Why does deep learning require substantial data and computing resources?
Objectives
- Describe what an artificial neural network is using an analogy.
- Explain what “deep” means in deep learning.
- Identify types of tasks that deep learning excels at.
- Understand why deep learning requires a lot of data and computing power.
What is a Neural Network?
Deep learning is built on a concept called the artificial neural network.
The name comes from a loose analogy with biology. In the human brain, neurons receive signals from other neurons. If the combined incoming signal is strong enough, the neuron “fires” and passes a signal onwards.
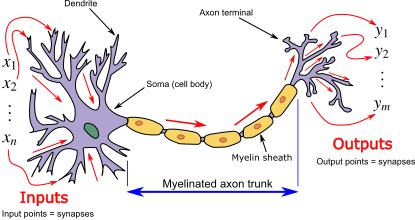
An artificial neuron works in a simplified mathematical way:
- It receives numbers as inputs.
- Each input is multiplied by a weight, which represents its importance.
- These weighted values are added together.
- If the result is large enough, the neuron produces an output.
- That output is then sent to the next layer.
Both biological and artificial neurons act as filters that combine many incoming signals, weighted by importance, and decide whether the combined signal should be passed to the next layer and, if so, how strongly the it should be passed on.
A single artificial neuron is rarely useful on its own. But, if you arrange many neurons together, you get a layer, and if you stack multiple layers you get a neural network. It is the depth of the layer stacking that gives deep learning its name and its power.
Layers and Depth
A neural network is typically organised into three types of layers:
- An input layer, which receives the raw data.
- One or more hidden layers, where most of the computation happens.
- An output layer, which produces the final prediction.

As data passes through the network, each layer transforms it into a slightly more abstract representation.
For example, in image recognition:
- An early layer might detect simple edges and lines.
- A later layer might detect shapes or textures.
- A deeper layer might detect complex structures such as faces.
In text processing:
- Early layers might detect characters or short word patterns.
- Middle layers might represent words or phrases.
- Later layers might capture aspects of meaning or context.
This hierarchical pattern detection is one of the main strengths of deep learning.
The word deep simply refers to the number of hidden layers. A shallow model might have one hidden layer. A deep model may have dozens or even hundreds of layers.
Types of Neural Network
There are many neural network architectures, each suited to particular tasks. Just a few common examples are discussed below.
Convolutional Neural Networks (CNNs)
CNNs are particularly effective for image and video analysis. They use specialised layers that focus on local patterns, such as edges and textures. Image classification tools are built on this type of architecture.
Some examples of CNNs being used for image analysis in research include:
- Analysing satellite imagery to detect environmental change.
- Identifying cell structures in microscopy images.
- Digitising and classifying historical documents.
- Transcribing and analysing handwritten documents
Recurrent Neural Networks (RNNs)
RNNs were designed to handle sequential data, such as time-series measurements or text. They process information step by step, maintaining a form of internal memory. In many applications, they have now been replaced by more advanced architectures.
Transformers
Transformers are the foundation of most modern natural language processing systems. They are especially effective at modelling relationships within sequences of text and form the basis of contemporary large language models, which we will examine in the next episode.
To read more about different neural network architectures have a look at the Neural Network Zoo, a cheat sheet for neural network architectures.
Training a Neural Network
During training, a neural network follows a repeated cycle.
- The network receives an input and produces a prediction.
- The prediction is compared with the correct answer.
- The difference between them is calculated as an error.
- This error signal is sent backwards through the network (known as backpropagation).
- The weights are adjusted slightly to reduce future errors.
This process is repeated across many times and on many examples, often millions.
Try Training a Neural Network
You can experiment with the process of training a neural network interactively using tools such as Tensorflow Playground.
The main task in TensorFlow Playground is classification: the network is trying to learn to separate two groups of data points (shown as orange and blue dots) by finding a boundary between them.
What the colours mean
The data points (the small circles on the graph) are coloured orange or blue to show which group they belong to.
The background colour of the output panel shows what the network is currently predicting for every possible point on the graph. If an area is blue, the network would classify any point there as belonging to the blue group. If it is orange, it would classify it as orange. The deeper and more saturated the colour, the more confident the network is in that prediction.
As training progresses, watch how the background pattern shifts and sharpens. This is the network adjusting its internal weights and gradually learning a better boundary between the two groups.
The lines connecting neurons in the hidden layers show the weights of the connections between neurons. A blue line means the connection has a positive weight and so the signal is passed forward and amplified. An orange line means the connection has a negative weight and so the signal is inverted or suppressed. Thick lines indicate strong weights in either direction whereas thin lines indicate weak ones.
What to try
- Press the play button and watch the network train. Notice how the background pattern in the output panel gradually changes as the network improves. The epoch counter shows how many times the network has passed through the training data.
- Try using a dataset with more complex boundaries - does increasing the number of features, hidden layers and/or neurons allow the neural network to learn more complex boundaries?
How can I Train My Own Deep Learning Model?
Training a deep learning model from scratch is significantly more demanding than training a conventional machine learning model, but it is not out of reach for motivated researchers, particularly with access to institutional computing infrastructure and Research Software Engineering support. More commonly, researchers work with pre-trained models and adapt them, rather than training from scratch.
What skills this requires
Deep learning requires all of the skills needed for conventional machine learning (programming in Python, data preparation, evaluation) plus additional capabilities. You will need familiarity with a deep learning framework such as PyTorch or TensorFlow, both of which have extensive documentation and active research communities.
Access to appropriate hardware is a practical requirement. Modern neural networks use very large datasets, contain millions of adjustable parameters, and iterate thousands of time. Therefore, training deep learning models on a standard laptop CPU is rarely feasible for research-scale tasks. Most researchers use GPUs, either through institutional high-performance computing (HPC) facilities or cloud platforms such as Google Colab, which provides free GPU access for smaller experiments.
Experiment management becomes important at this level of complexity. Tracking which model configuration produced which results, managing large datasets, and handling training runs that may take hours or days requires a great deal of organisation and tools such as Weights & Biases or MLflow.
Deep learning also demands a somewhat deeper understanding of model architecture and training dynamics than conventional ML. You need enough conceptual understanding to diagnose when training is going wrong, for example, when a model is failing to learn, overfitting, or producing unexpected outputs.
Choosing the Right Machine Learning or Deep Learning Model: Interpretable Models vs Black Box Models
Before choosing a machine learning approach, one of the most important questions to ask is:
“Do I need to understand why the model makes a particular prediction, or is the prediction itself sufficient?”
This is the distinction between interpretable and black box models.
An interpretable model produces outputs that can be traced back to a clear, human-readable explanation. A linear regression, for instance, gives you a coefficient for each input variable and you can see directly how much each factor contributed to the prediction. A decision tree reaches its conclusion through a series of simple yes/no rules that can be printed out and inspected. When your research requires accountability, transparency, or regulatory compliance, interpretability may be essential.
A black box model, such as a deep neural network with many layers, may produce highly accurate predictions, but the internal reasoning process is not directly accessible. You can observe the inputs and outputs, but the path between them involves thousands or millions of interacting numerical parameters that do not correspond to human-understandable concepts.

Consider an interpretable model when:
- You need to explain or justify individual predictions
- Your field has regulatory or ethical requirements for transparency
- Discovering which variables matter is part of the research question
- Stakeholders (e.g. patients, policymakers, or funders) need to understand the rationale
A black box model may be acceptable when:
- Predictive accuracy is the primary goal
- Outputs will be validated independently before acting on them
- Large volumes of complex data (images, audio) make interpretability impractical
- Artificial neural networks consist of layers of weighted computational units inspired by biological neurons.
- ‘Deep’ refers to having multiple hidden layers that learn increasingly abstract representations.
- Training involves making predictions, measuring error, and adjusting weights using backpropagation.
- Deep learning excels at complex pattern recognition tasks such as image, audio, and text analysis.
- Large models require extensive data and computing resources to train effectively.
References
Content from Large Language Models
Last updated on 2026-07-06 | Edit this page
Estimated time: 35 minutes
Overview
Questions
- What is a large language model and how does it relate to deep learning?
- How are LLMs trained, and what does “large” actually mean?
- Why do LLMs sometimes produce confident but incorrect information?
- What are the key limitations I should understand before using an LLM in my research?
Objectives
- Explain what an LLM is and where it sits within the broader AI landscape.
- Describe the Transformer architecture and the attention mechanism.
- Distinguish between pre-training and fine-tuning.
- Define hallucination, knowledge cutoff, and context window, and explain why they matter for research use.
Introduction
Over the previous two episodes we have built up a picture of how machines can learn from data, and how deep neural networks can learn rich, layered representations of the world. In this episode we apply those ideas to language. We will explore Large Language Models (LLMs), the technology behind tools such as ChatGPT, Claude, Gemini, and Copilot, to understand what they are, how they are built, and what their real limitations are.
By the end of this episode you will be in a much stronger position to use these tools critically and responsibly in your own research
What is a Large Language Model?
A Large Language Model is a type of deep learning model trained on vast quantities of text, with the goal of learning how language works so that it can generate and respond to text in a coherent, useful way.
The word “large” refers to two things at once:
- The training data: modern LLMs are trained on trillions of words drawn from books, websites, academic papers, code repositories, and more.
- The number of parameters: parameters are the adjustable weights inside the network that are learned during training. Leading models have hundreds of billions, or even trillions, of these values.
Putting “large” in perspective
One trillion is 1,000,000,000,000. To give a sense of scale: if you counted one parameter per second without stopping, counting to one trillion would take over 31,000 years. The sheer number of parameters is what allows these models to store and manipulate rich, nuanced representations of language.
Despite their apparent sophistication, LLMs are trained on a surprisingly simple objective: given a sequence of words, predict what word is most likely to come next.
Consider the sentence:
The researcher submitted her manuscript to the…
A well-trained model should assign a high probability to words like journal or publisher, and a low probability to words like submarine or Tuesday. By doing this billions of times across an enormous training corpus, the model is forced to learn grammar, facts, writing conventions, and even something resembling reasoning because all of these are encoded in the statistical patterns of language.
This is sometimes called self-supervised learning: the training data provides its own labels (the next word is always known from the text itself), so no human annotation is required.
Transformer Architecture
LLMs are built on an architecture called the Transformer, introduced in a landmark 2017 paper titled “Attention Is All You Need” (cited over 234,000 times as of Spring 2026) written by researchers working for Google. Before the Transformer, models processed text one word at a time, which:
- was slow
- made it hard to capture relationships between words that were far apart in a sentence.
The Transformer solved both problems.

The Attention Mechanism
The key innovation of the Transformer is the attention mechanism. Rather than processing words in isolation, attention allows the model to look at all the words in a passage simultaneously and learn which ones are most relevant to understanding each particular word.
Consider this sentence:
The bank was steep and muddy, so she slipped climbing down it.
When processing the word bank, a human reader immediately uses context clues such as steep, muddy, and climbing, to understand that this is a riverbank, not a financial institution. The attention mechanism allows a Transformer to do something similar: it learns to assign higher attention weights to the words most relevant for correctly interpreting each part of the text.
The attention mechanism combined with the availability of large-scale computing hardware, triggered a step up in what language models could do. Essentially all major LLMs today including ChatGPT, Claude, and Gemini are built on the Transformer architecture.
How LLMs Are Trained: Pre-training and Fine-tuning
Stage 1: Pre-training
In the pre-training stage, the model is trained from scratch on an enormous, general-purpose body of text. The training objective is to predict the next word. The model adjusts its billions of parameters through backpropagation (the backward flow of error through a neural network, see Episode 3) until it becomes very good at predicting text across a huge range of topics and styles.
Pre-training is extremely resource-intensive. Training a leading LLM can:
- Require thousands of specialised computer chips running in parallel for weeks or months.
- Consume millions of pounds’ worth of electricity and hardware time.
- Produce a significant carbon footprint. One study found that training a single large transformer model can emit over 283,000 kg of carbon
This cost means that pre-trained models are rarely trained from scratch by individual researchers or institutions. Instead, organisations release pre-trained base models that others can build on.
This bar plot below is from the Stanford Institute for Human-Centered Artificial Intelligence 2024 AI index. It shows the rapid increase in the computing cost of training large language models.
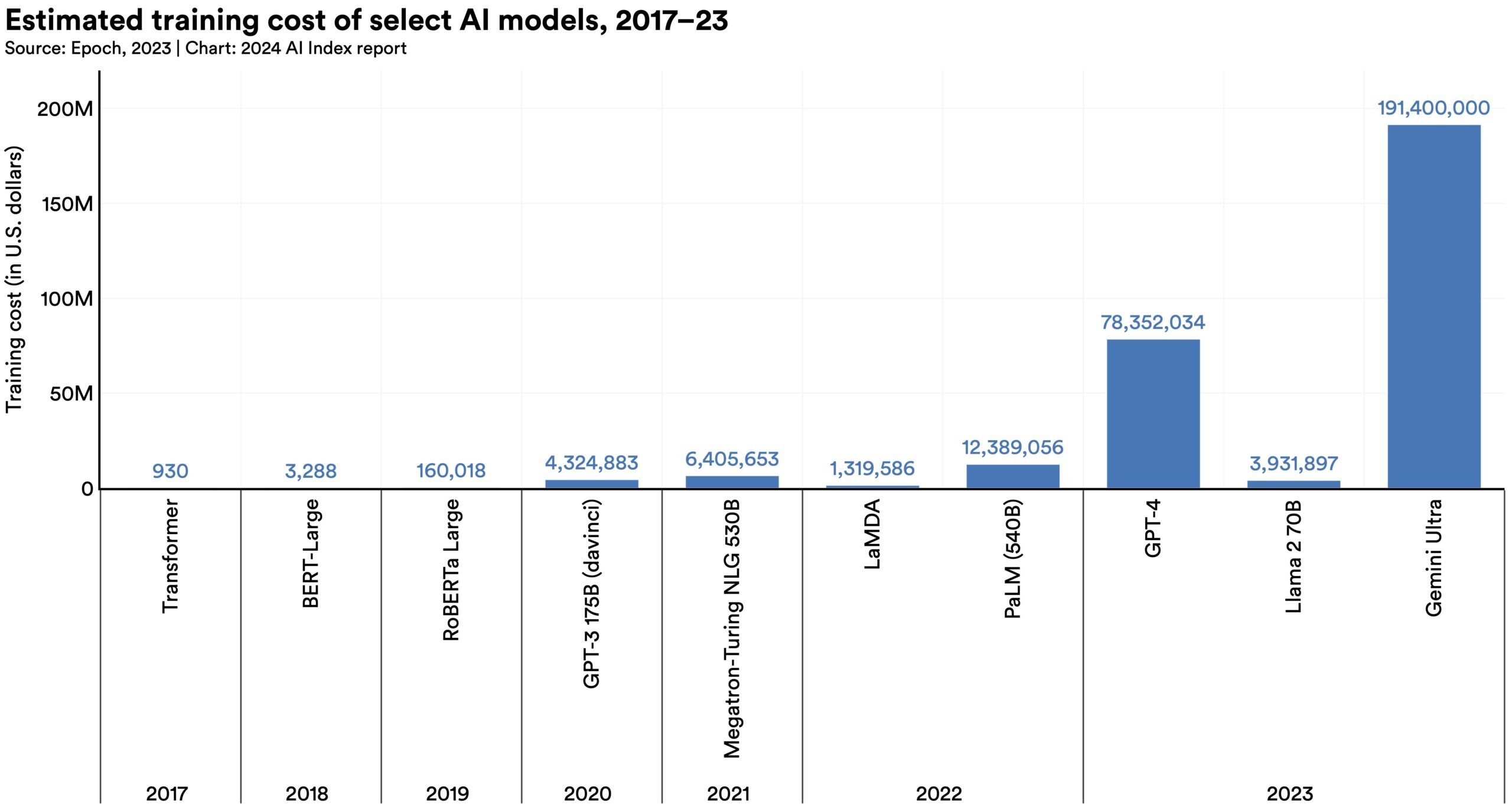
Stage 2: Fine-tuning
Once a base model exists, it can be fine-tuned. This means it can be trained further on a smaller, more targeted dataset to adapt its behaviour for a specific purpose or domain. For example, a base model might be fine-tuned:
- on medical literature to improve its performance on clinical questions.
- on legal documents to better support contract analysis.
- using human feedback to make it more helpful, harmless, and honest in conversation.
That last approach, of using human ratings to guide the model toward more desirable outputs, is called Reinforcement Learning from Human Feedback (RLHF). It is largely responsible for the conversational, ‘helpful assistant’ style of tools like ChatGPT. Human raters score model outputs, and the model is trained to produce outputs that score more highly.
Pre-training and Fine-tuning Analogy
Think of pre-training as an undergraduate education: the student reads broadly across many subjects and develops general knowledge and reasoning skills. Fine-tuning is then like a postgraduate specialisation: the student goes deep into a specific field, building on their broad foundation.
A model trained this way inherits both the strengths and the limitations of its pre-training. If the pre-training data contained biased, outdated, or incorrect material, those properties will be present in the base model and may persist even after fine-tuning.
What LLMs Can Do
LLMs have demonstrated some amazing capabilities across a wide range of language tasks, including:
- Text generation and summarisation — producing coherent text, summarising long documents, drafting emails.
- Question answering — responding to factual queries based on patterns in training data.
- Translation — converting text between languages.
- Code generation — writing, explaining, and debugging computer code.
- Step-by-step reasoning — working through multi-step problems when prompted appropriately.
- Information extraction — identifying entities, relationships, or themes in text.
For researchers, LLMs offer potential value in tasks such as summarising literature, drafting sections of text for revision, assisting with qualitative coding, generating data analysis computer code, and exploring ideas interactively.
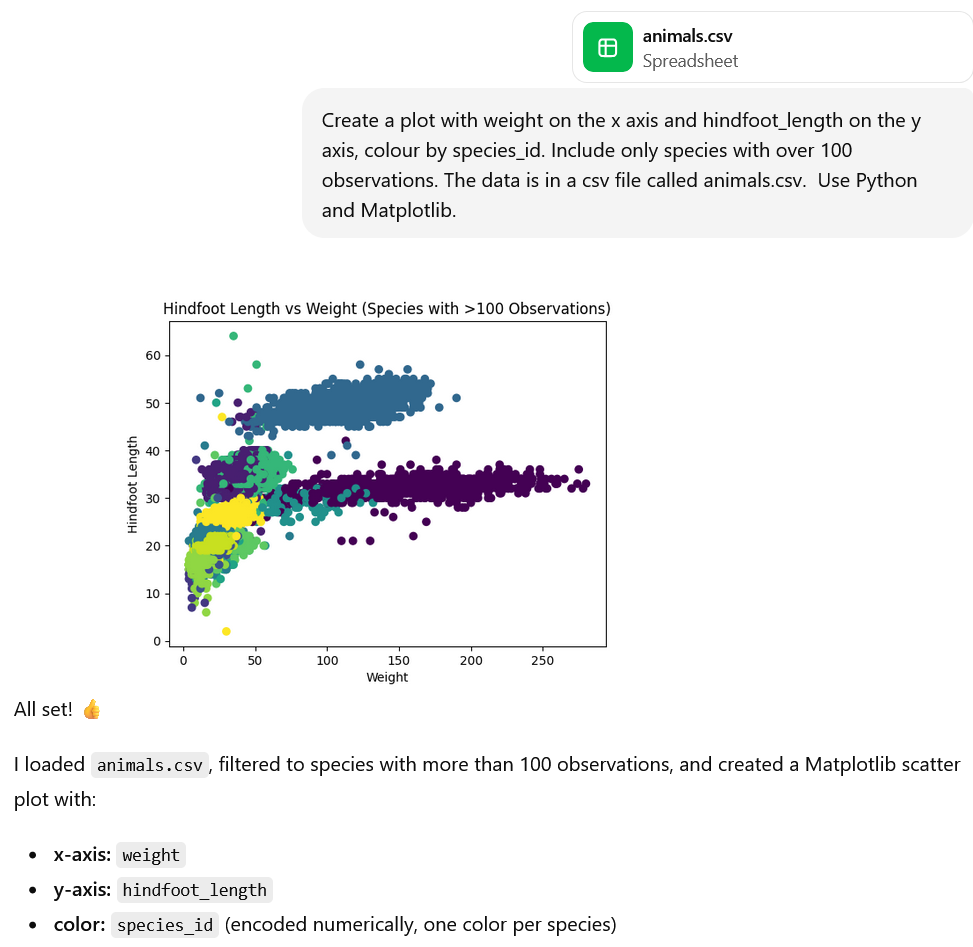
For example, given a dataset, an LLM can generate code for tasks such as data analysis. Generative AI tools can even run the code as well! This is incredible but we should be cautious when outsourcing these tasks to LLMs due to several limitations that we will discuss below.
What LLMs Cannot Do: Key Limitations
Understanding what LLMs cannot reliably do is at least as important as knowing what they can do, especially for research applications where accuracy and reproducibility matter.
Hallucination
Perhaps the most important limitation to understand is hallucination: LLMs often generate confident, fluent, plausible-sounding text that is factually incorrect.
This is not an occasional bug that will eventually be fixed, it is a fundamental property of how these models work. An LLM is optimised to produce coherent, contextually appropriate text but it is not optimised to produce truth. It has no direct access to a database of facts it can look up. Instead, it generates text by predicting what is most likely to come next, based on patterns learned during training.
In practice this means an LLM might:
- Invent citations to academic papers that do not exist, complete with plausible-sounding titles, authors, and journal names.
- State incorrect dates, statistics, or quotations with complete confidence.
- Describe the findings of a study inaccurately, even when the study is real.
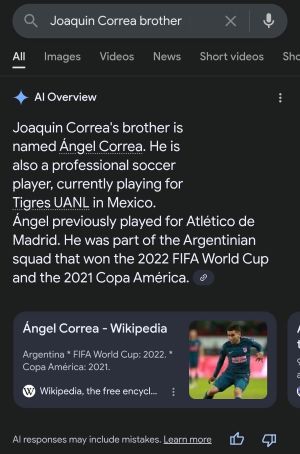
For example, the Google AI Overviews result (10 August 2025) incorrectly stated that Joaquín Correa is the brother of Ángel Correa while in reality the two are unrelated.
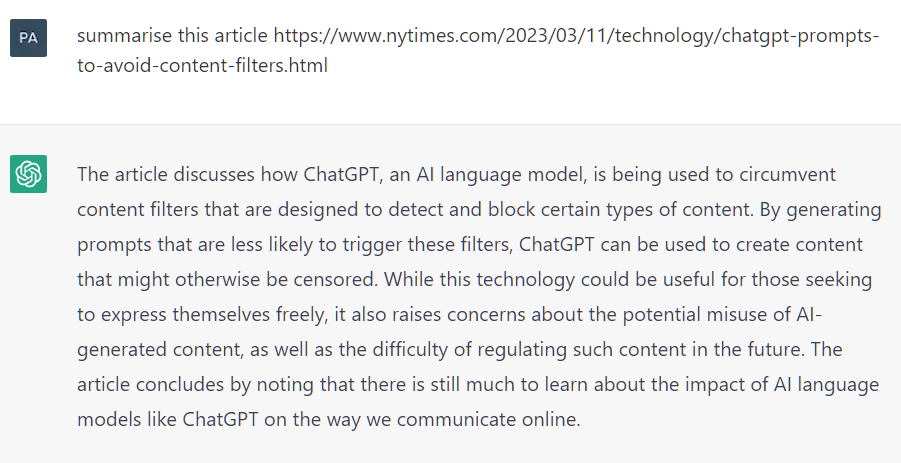
Another example - when prompted to “summarize an article” with a fake URL that contains meaningful keywords, even with no Internet connection, ChatGPT generates a response that seems valid at first glance.
Why is it called ‘hallucination’?
The term is borrowed from psychology, where hallucination refers to perceiving something that is not actually there. When an LLM “hallucinates”, it generates content that feels real and is presented confidently, but has no basis in fact. The model has no way to flag its own uncertainty in the way a cautious human expert might say “I’m not certain, but I believe…”. That’s why it’s important to verify factual claims from LLMs using primary sources.
Knowledge Cutoff
LLMs are trained on data collected up to a specific point in time, this is known as their knowledge cutoff date. They have no awareness of events, publications, or developments that occurred after that date, unless they are connected to external tools such as a web search capability.
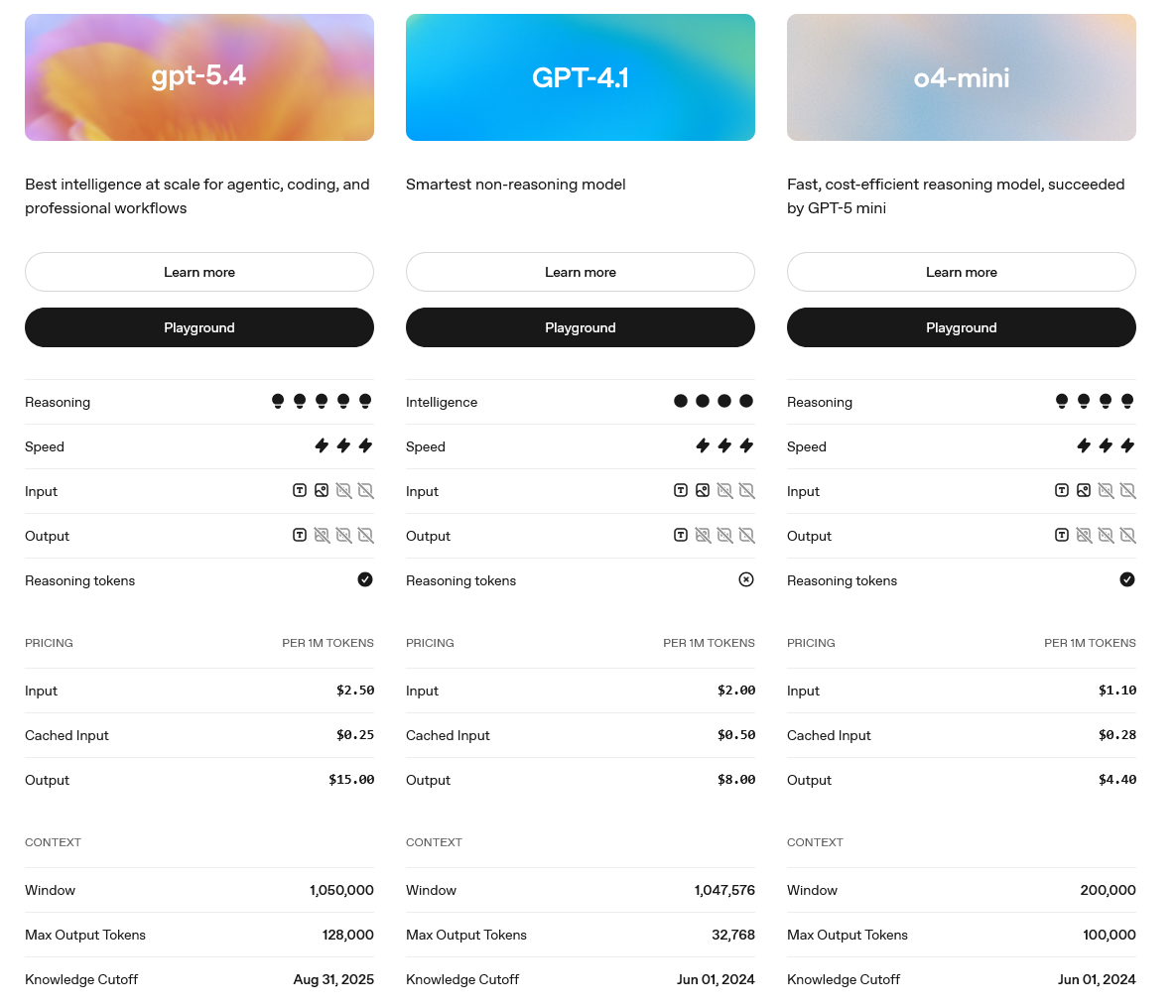
For example, GPT-5.4 (the latest OpenAI model as of March 2026) has a knowledge cutoff of August 31st 2025 and GPT-4.1 has a knowledge cutoff of 1st June 2024 (OpenAI Developers - Compare Models).
This matters particularly for research, where the most recent literature may be the most relevant. An LLM asked about the current state of a fast-moving field may give a confident account that is months or years out of date.
Stochasticity: Different Answers Each Time
LLM outputs are probabilistic rather than deterministic. Even when given exactly the same input, an LLM will often produce a different output on subsequent runs. This has implications for reproducibility in research: if you use an LLM in your methodology, you cannot guarantee that re-running your analysis will produce identical results.
Context Window
Every LLM has a context window, which is the maximum amount of text it can “see” and process at one time. You can think of it as the model’s working memory for a single interaction. If you provide a document that exceeds the context window, the model may be forced to ignore parts of it, potentially affecting the quality of its output.
Context window sizes vary widely across models and have grown considerably in recent years, but they remain a practical constraint when working with very long documents.
The context window for the free tier of ChatGPT using the model ‘GPT-5.3 Instant’ is 16,000 tokens (words, parts of words or punctuation), whereas the context window of ‘GPT-5.4 Thinking’ is 400,000 tokens (OpenAI Help Docs)
No Genuine Understanding
Finally, it is important to resist the temptation to interpret LLM fluency as understanding. An LLM produces text by sophisticated pattern matching and it does not have beliefs, intentions, or knowledge in the way a human expert does. A model that can write a convincing paragraph about quantum mechanics has not ‘understood’ quantum mechanics, it has just learned what such paragraphs tend to look like.
Summary of key LLM limitations
| Limitation | What it means in practice |
|---|---|
| Hallucination | Outputs may be confidently wrong; always verify factual claims |
| Knowledge cutoff | The model is unaware of events after its training data ends |
| Stochasticity | The same question can produce different answers |
| Context window | Very long documents may be partially ignored |
| No verified understanding | Fluency does not equal accuracy or expertise |
Challenge: True or False?
For each statement below, decide whether it is true or false, and briefly explain your reasoning.
- When an LLM answers a question, it searches the internet and retrieves the most relevant facts.
- A fine-tuned LLM trained on medical literature will always give accurate medical information.
- Two researchers using the same LLM with the same prompt will always receive identical outputs.
False. A standard LLM generates responses based on patterns learned during training — it does not retrieve information from a live database or the internet. Some LLMs are connected to web search tools, but this is an added capability, not a core feature of how the model works.
False. Fine-tuning on domain-specific text can improve performance in a given area, but it does not eliminate hallucination. A model can still produce confident but incorrect medical information. Domain expertise does not guarantee accuracy.
False. LLM outputs are probabilistic. The same input can produce different outputs across different sessions, or even within the same session, because the model samples from a distribution of possible next words rather than selecting a single deterministic answer.
Testing the Limitations of LLMs
Go to a conversational AI tool such as ChatGPT, Microsoft Copilot or Claude and ask the following questions:
- Ask the model to provide three references on a niche academic topic. Note any invented or inaccurate citations.
- Ask the same question twice and compare outputs.
- Ask about a very recent event, publication, or development in your field and observe how the model responds. Does it admit uncertainty, speculate, give outdated information, or turn to web search capabilities?
- Ask the model to summarise a short paragraph you provide. You could use the paragraph above about the attention mechanism or provide one of your own.
- Possibility of hallucination
- Stochasticity demonstration - two responses to the same prompt are likely to differ.
- Knowledge cutoff demonstration - LLMs only have knowledge of events prior to when they were trained.
- This illustrates a task where LLMs usually do well.
Could I Build or Fine-Tune My Own LLM?
For most researchers and institutions, training an LLM from scratch is not realistic. The compute and financial resources required place it firmly in the domain of large technology companies. However, there are several meaningful ways researchers can work with and adapt language models without training one from scratch.
What skills this requires
Fine-tuning a language model requires all of the skills described in the deep learning section above, plus familiarity with the specific landscape of large language model tooling. This may include the Hugging Face ecosystem, which provides pre-trained models, fine-tuning utilities, datasets, and deployment infrastructure that have become the de facto standard for research-scale language model work.
Working with large datasets of text introduces additional challenges. Cleaning and de-duplicating large amounts of text, handling tokenisation, and managing data pipelines that may involve hundreds of gigabytes of text. These problems involve software engineering skills as well as machine learning expertise.
For fine-tuning, understanding the task you are optimising for matters a lot. You’d need to carefully design the approaches for determining which data to use and how to evaluate the model.
The Hugging Face ecosystem
Hugging Face is the primary hub
for open-source language model research. It hosts thousands of
pre-trained models, datasets, and fine-tuning tools, and its
transformers library is the standard Python interface for
working with language models in research. If you are considering any
form of language model work, this is the most important resource to be
aware of. The Hugging Face NLP Course is a free
introductory course on working with language models in code.
Summary
In this episode we have seen how the simple task of predicting the next word can lead to the powerful, general-purpose language tools that are reshaping how people interact with information today.
In Episode 5, we will bring together everything from the course to explore how AI tools, including LLMs, are being used in research today, and how to evaluate them critically and ethically.
- LLMs are deep learning models trained on massive text datasets to predict the next word, from which broad language capabilities emerge.
- The Transformer architecture, and its attention mechanism, is the foundation of all major modern LLMs.
- Pre-training builds general language knowledge; fine-tuning specialises a model for particular tasks or behaviours.
- LLMs hallucinate — they generate confident but factually incorrect content — because they are optimised for coherent text, not verified truth.
- LLMs have a knowledge cutoff date and are unaware of more recent events unless equipped with external search tools.
- Outputs are probabilistic: the same prompt can produce different responses, with implications for research reproducibility.
References
Content from AI in Research
Last updated on 2026-07-08 | Edit this page
Estimated time: 60 minutes
Overview
Questions
- What questions should I ask before adopting an AI tool in my research workflow?
- What ethical responsibilities do I have as a researcher using AI?
- How do I handle transparency and reproducibility when AI has been part of my methodology?
Objectives
- Apply a set of critical evaluation questions to any AI tool before adopting it.
- Describe the key ethical concerns raised by the use of AI in research, including bias, transparency, privacy, and attribution.
- Explain why reproducibility is a particular challenge when AI is part of a research workflow.
Considerations When Working with AI
Bias and Fairness
AI models do not arrive in the world as neutral tools. They are trained on data generated by human societies, and those societies contain historical and structural inequalities. A model trained on historical medical records will reflect historical disparities in who received care and who was documented. A model trained on published academic literature will reflect who has historically had access to publish.
The consequences can be serious. Models used for clinical risk prediction have been shown to perform worse on patients from groups underrepresented in the training data. Automated tools used in hiring or admissions have reproduced patterns of discrimination from historical decisions.
Amazon’s AI Recruiting Tool
One of the most widely cited examples of AI bias comes from Amazon. Beginning in 2014, Amazon built an experimental AI tool designed to screen job applicants’ resumes and rate candidates from one to five stars, with the goal of automating part of its hiring process for technical roles.
The system was trained on roughly a decade of resumes the company had previously received. Because the tech industry is male-dominated, the majority of those resumes came from men, and the system learned to favour male candidates over female ones. In practice, this meant the tool downgraded resumes that included the word “women’s” — such as “women’s chess club” — and penalised graduates of certain all-women’s colleges.
Racial Bias in Health Algorithms
Researchers found evidence of racial bias in one of the most widely used algorithms in the US health care system.
For patients assigned the same level of risk by the algorithm, Black patients were sicker than White patients. The authors estimated that this racial bias reduces the number of Black patients identified for extra care by more than half. This bias occurs because the algorithm uses health costs as a proxy for health needs. Less money is spent on Black patients who have the same level of need, and the algorithm thus falsely concludes that Black patients are healthier than equally sick White patients. Reformulating the algorithm so that it no longer uses costs as a proxy for needs eliminates the racial bias in predicting who needs extra care (Obermeyer et al., 2019).
Privacy and Data Governance
Many AI tools, particularly cloud-based LLMs, process data on external servers. If you input sensitive data such as patient records, interview transcripts, or confidential documents, into a commercial AI tool, you may be:
- Breaching participant confidentiality.
- Violating data protection legislation such as the UK GDPR.
- Contravening your institution’s data governance policies or your ethical approval conditions.
Before inputting any data into an AI tool, check your institution’s and research group’s guidance on what categories of data may be processed in this way, and review the tool provider’s privacy and data retention policies.
Attribution and Authorship
LLMs have raised genuinely novel questions about authorship and attribution that the research community is still working through. Key issues include:
- Authorship of AI-generated text: most major publishers and funders now have explicit policies stating that AI tools cannot be listed as authors, because authorship carries accountability that an AI model cannot hold. However, policies on disclosing the use of AI in drafting or editing text vary and are evolving rapidly.
- Attribution of AI-generated analysis: if an LLM assists with qualitative coding or data interpretation, how should that contribution be disclosed in the methods section?
- Copyright in training data: LLMs are trained on text that may include copyrighted material. The legal and ethical status of this is an active area of debate. By including AI-generated text or code in your research, you may inadvertantly be infringing copyright.
You should check the current policies of your target journal or funder, and your institution’s own guidance, before submitting work in which AI has played a role.
Publisher’s Stance on AI Use in Academic Research
Summarised from - Rana, N. K. (2025). Generative AI and academic research: A review of the policies from selected HEIs.
Cambridge University Press: AI tools cannot be credited as authors, and authors remain fully responsible for the accuracy, integrity, and originality of their work.
Nature Portfolio: AI tools are not permitted as authors, their use must be transparently disclosed, and AI-generated images are generally prohibited due to unresolved legal and ethical concerns. Nature requires disclosure of LLM use in the Methods section (or an equivalent section), rather than in acknowledgements or citations.
Elsevier: Elsevier allows AI-assisted tools for writing support, limited to improving clarity and readability. However, core scholarly activities, such as generating scientific insights, drawing conclusions, or making recommendations, must remain human-led. Elsevier requires authors to declare any AI tool usage and does not allow AI tools to be listed as authors.
Citation
The outputs of AI aren’t stable, they’re likely to vary depending on prompt wording and the AI model version among other factors. Therefore, they can’t be reliably cited in the same way as you would cite a research paper or software package.
Several universities and libraries recommend citing the tool used including the version and date, and describing how it was used. Many AI tools now allow chats to be shared through URLs, meaning that specific chats can be cited if that would be appropriate and helpful to readers of the research.
Duke University Libraries gives the following guidance on how to cite an AI Chat and AI Tool in several different referencing styles. For example, the APA style would be:
AI Chat
AI Company Name. (Year, Month Day). Title of chat [Description, such as Generative AI chat]. Tool Name/Model. URL of the chat.
Example: OpenAI. (2025, August 21). High school grammar concepts [Generative AI chat]. ChatGPT. https://chatgpt.com/share/68a77b60-0ee4-800c-9acc-cd3fd573c311
AI Tool
AI Company Name. (Year). Tool Name/Model [Description: e.g., Large language model]. URL of the tool
Example: OpenAI. (2025). ChatGPT [Large language model]. https://chatgpt.com/
Critically Reviewing AI Use in Qualitative Research
Scenario: You are reviewing a manuscript submitted to your field’s leading journal. In the methods section, the authors write:
“Qualitative thematic analysis of interview transcripts was supported by an AI language model, which was used to generate initial codes. These codes were then reviewed and refined by the research team. The AI tool assisted with the analysis of all 47 transcripts.”
Discuss the following questions:
- What information is missing from this methods description that you would need as a reviewer?
- What risks or limitations should the authors have acknowledged?
Information that is missing:
- Which AI tool was used, and which version? (Without this, the approach cannot be evaluated or replicated.)
- What prompts or instructions were given to the model?
- How were AI-generated codes accepted, modified, or rejected?
- Was the tool validated on similar data or in similar research contexts?
- How was participant data handled? Was it anonymised before being input? Was the tool’s data retention policy checked against ethical approval conditions?
Risks and limitations the authors should have acknowledged:
- LLMs can produce plausible-sounding codes that do not accurately reflect the content of the transcript.
- The model may perform inconsistently across different transcripts, introducing variability that is difficult to detect.
- The model’s outputs may reflect biases in its training data rather than patterns in the research data.
- If the same analysis were run again, the model might produce different initial codes.
Cognitive Offloading and De-skilling with Generative AI
AI tools are incredibly useful for research but there’s a risk that’s easy to overlook: the less we do something ourselves, the less capable we become at doing it. This phenomenon has been called cognitive offloading and it isn’t a new issue. For example:
- Calculators → we practice mental arithmetic less
- GPS → we build less internal sense of geography
Sometimes that trade-off is fine. However, research depends on thinking carefully, critically, and independently, so it’s important to consider whether the trade-off is worth it here.
Example: AI-generated code
If you use code to process data or run analyses, that code is part of your methodology.
- If you didn’t write it and don’t fully understand it, you can’t be 100% confident in your results.
- AI-generated code can contain subtle errors that produce plausible-looking but wrong results
- A researcher who understands the code can catch these errors but one who doesn’t, might not
- Those errors can directly affect your results
More generally, every time we outsource a cognitive task to an AI, we don’t get the practice at doing it ourselves. Over time, this can make us lose the underlying skill.
- A researcher who always asks an LLM to summarise papers may gradually lose the habit of reading them carefully.
- A researcher who always asks an LLM to draft text may find their own writing voice harder to find.
Research depends on deep and independent thinking. To do good research, researchers need to sit with a difficult problem, reason through it and arrive at your own conclusions. Using AI thoughtfully involves deliberate decisions about which tasks to outsource to AI and which to do yourself, not because an AI couldn’t do it, but because it’s a part of your human intelligence that you’d like to protect.
AI Impact on Critical Thinking
A large mixed-methods study investigated the impact of AI usage on critical thinking skills using surveys and in-depth interviews.
It was found that AI tool use was significantly negatively associated with critical thinking abilities and that this association was mediated (explained) by increased cognitive offloading.
The author argues that ‘these results highlight the potential cognitive costs of AI tool reliance, emphasising the need for educational strategies that promote critical engagement with AI technologies.’
Environmental Cost of AI
The environmental cost of AI is larger and more complex than most users appreciate.
AI tools run on data centres. These are large warehouses full of powerful computers that store data and run the calculations behind everyday digital services, including AI systems like chatbots. Data centres need large amounts of electricity to power the computers and, because these computers generate a lot of heat when running, they also require large amounts of water to keep them cool.
Due to increasing demand, data centres could consume up to 9% of global electricity demand by 2030 (Hankendi et al., 2025). AI systems are the fastest-growing source of this demand, but measuring their precise impact is difficult because operators rarely separate AI computing tasks (often called ‘workloads’) from non-AI computing tasks (workloads) in their environmental reporting.
The most recent estimates suggest that in 2025, AI systems generated carbon emissons comparable to the annual emissions of a major city (up to 79.7 million tonnes of carbon) and consumed an amount of water comparable to global bottled water consumption (up to 764 billion litres of water) (de Vries-Gao, 2025).

Environmental costs accumulate across the full lifecycle of an AI model. This includes the water and carbon used to manufacture the specialist chips required to run the AI; the intensive one-off cost of training the model; and the ongoing costs of inference (the cost every time a query is run).
Lifetime costs: Embodied carbon (the carbon produced from manufacturing the hardware) can account for a significant fraction of the overall environmental cost of the model, but it is challenging to calculate and seldom reported.
Training: A 2019 study found that training a single large transformer model can emit over 283,000 kg (626,000 pounds) of carbon, which is roughly equivalent to five times the lifetime emissions of an average American car (including the emissions from building the car!).
Inference: Although many people believe that initial training has the largest environmental cost, recent studies have found that inference can actually account for up to 90% of a model’s lifetime energy use (Desislavov et al., 2023). Water consumption follows a similar pattern, with estimates suggesting a standard ChatGPT conversation of 20–50 exchanges requires roughly 500 millilitres of freshwater for cooling the servers in data centres (Li et al., 2023).
Not all AI is equally environmentally expensive. General-purpose LLMs are orders of magnitude more energy-intensive per inference than smaller, task-specific models performing the same job. This means that the convenience of using a single general-purpose LLM interface can carry a substantial and largely invisible environmental cost when multiplied across many uses. A fine-tuned model used for classification or information extraction may produce comparable results at a fraction of the per-query energy cost (Luccioni et al., 2024).
Where the data centre is located also affects the environmental impact. A data centre draws electricity from its local grid and therefore its environmental footprint depends heavily on how the region in which it’s located generates power. A data centre on a grid powered mostly by renewables (wind, solar, hydropower) will have a far smaller footprint than an identical one on a grid powered mostly by fossil fuels, even when running exactly the same workload.
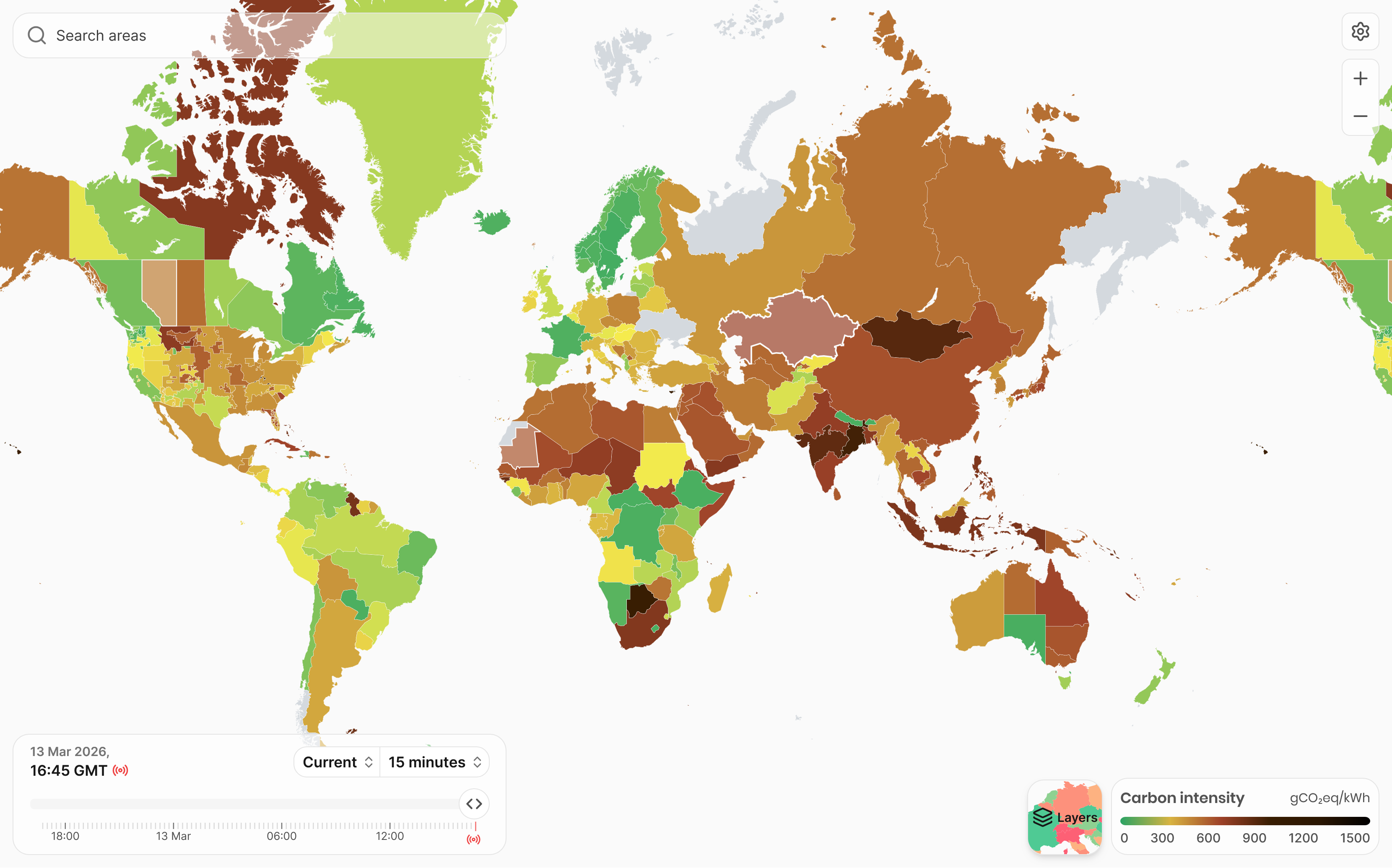
The Electricity Maps website maps the amount of greenhouse gas emitted for every unit of electricity produced for data centres across the world. Looking at the map, it’s clear that training an AI model in a data center in Scandinavia would have a lower environmental impact than training the model in Australia. Scandinavian grids rely heavily on hydropower and wind (low carbon intensity), while Australia’s still relies more on coal (much higher).
Renewable Energy Certificates
However, the relationship between renewable energy and AI’s actual carbon footprint is more complex than it first appears.
Many data centre operators claim to run on renewable energy by purchasing Renewable Energy Certificates (RECs), which allow them to offset their consumption on paper without necessarily drawing clean power from the grid in real time.
This distinction - between matching renewable energy and actually using it - has attracted significant criticism of major providers including Google and Microsoft (Bjørn et al., 2022).
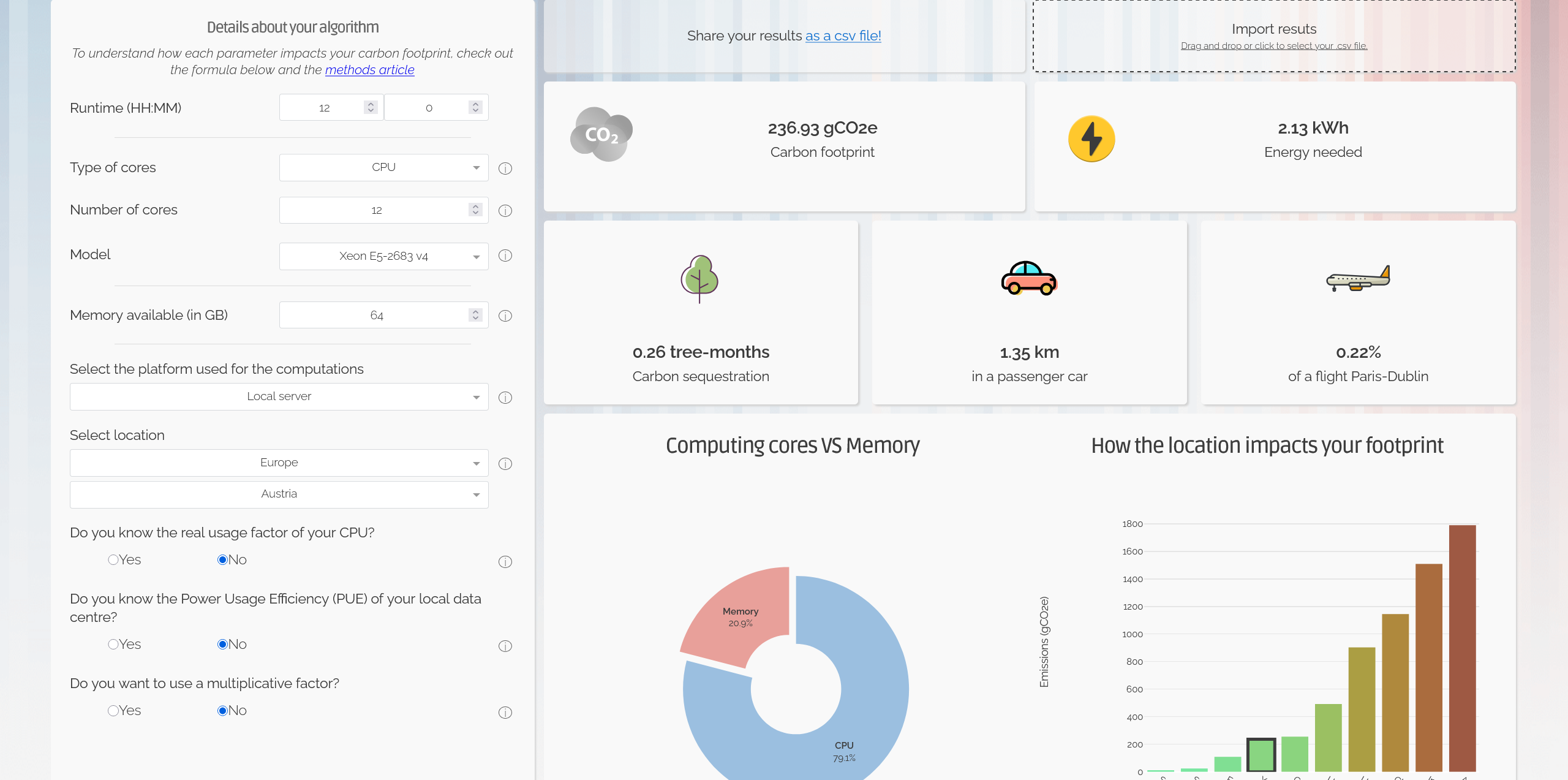
Some tools exist that can help developers better understand the cost of training and inference, for example in the Green Algorithms AI calculator users can enter details on the hardware, runtime, and location of the work and see the potential environmental cost: https://calculator.green-algorithms.org/ai.
Overall, the biggest obstacle to accurate environmental accounting for AI is the problem of transparency. The companies operating the largest AI systems publish very little useful data. Furthermore, the published per-query emissions figures from AI providers typically reflect optimised, market-based conditions rather than an accurate estimate of carbon and water usage (de Vries-Gao, 2025).
Until providers are required to report location-based emissions data transparently and consistently, the true environmental cost of AI will remain difficult to measure and easy to understate (Masanet et al., 2024).
Do the benefits of AI justify its environmental costs?
Do the benefits of AI justify its environmental costs? Where should we draw the line?
Benefits Justify Costs
- AI is already being used in climate-relevant applications: optimising energy grids, accelerating materials discovery for batteries and solar cells, improving weather and climate modelling, and monitoring deforestation via satellite imagery. These applications could meaningfully contribute to decarbonisation long-term.
- Drug discovery and medical diagnostics applications could save lives and reduce the resource burden of healthcare systems.
- Efficiency gains from AI in logistics, agriculture, and manufacturing may reduce emissions elsewhere in the economy, potentially offsetting AI’s own footprint.
Costs Outweigh Benefits
- The benefits of AI are often speculative or early-stage, while the environmental costs are immediate and certain. Should we be justifying present costs with uncertain future benefits?
- Many of the highest-energy AI applications, such as generating images, powering chatbots, and recommending content, have unclear societal benefit relative to their cost.
- Efficiency gains from new technologies have historically tended to increase overall consumption. This a phenomenon known as the Jevons paradox because in 1865, the English economist William Stanley Jevons observed that technological improvements that increased the efficiency of coal use led to the increased consumption of coal in a wide range of industries.
- The benefits of AI are unevenly distributed globally, while environmental costs, particularly water stress, fall disproportionately on communities that may derive little benefit from the technology.
Who decides where we draw the line?
- “Societal benefit” is not a neutral concept, it depends on whose society and whose benefits are being counted. Researchers, developers, regulators, and affected communities may weigh the trade-offs very differently.
- Individual researchers have limited power over the training of frontier models, but they do have agency over which tools they choose, how often they use them, and whether they advocate for greater transparency and accountability from providers.
- Should the decision be left to market forces, regulated by governments, or governed by professional communities such as researchers?
Where do we draw the line?
- Is it possible to draw a principled line, or does it require case-by-case judgement? A diagnostic AI that saves lives in a resource-limited setting may be easier to justify than a generative AI that writes marketing copy.
- Should the burden of proof lie with those deploying AI to demonstrate net benefit, or with critics to demonstrate net harm?
- Who bears responsibility? Is it the companies training the models, the institutions deploying them, or the researchers using them?
Looking Ahead: Developing Your AI Literacy
This course has given you a map of the AI landscape and the vocabulary to navigate it.
A few practical suggestions for developing your AI literacy beyond this course:
- Follow your institution’s guidance. Most universities and research funders are actively developing AI use policies. These are the most directly relevant to your work, and they will continue to evolve. For example, for researchers at the University of Southampton, point 3.8 of the Ethics Policy for Research at University of Southampton shows the Principle of ethical conduct of research when using Artificial Intelligence (AI) and students should also consult guidance on Using generative artificial intelligence during your studies.
- Engage with your research community. Methodological norms for AI use in research are being worked out discipline by discipline. Engaging with debates in your own field’s journals and conferences is more valuable than generic AI news.
- Start small and validate. If you are considering integrating an AI tool into your workflow, start with a small, low-stakes task and validate the outputs carefully before scaling up.
- Be transparent. When in doubt about how much to disclose about your use of AI, err on the side of transparency. The research community is better served by over-disclosure than by the opposite.
- Before adopting any AI tool, ask: what was it trained on? Has it been validated? Can results be reproduced? Can outputs be explained? What are the failure modes?
- AI models reflect the biases in their training data.
- Transparency in methods is essential: report which tools were used, at what version, for what purpose, and how outputs were validated.
- Privacy and data governance must be considered before inputting any sensitive or personal data into an AI tool.
- Authorship, attribution, and environmental cost are emerging ethical considerations that researchers should engage with actively.
- Consider the impacts on human intelligence when outsourcing tasks to AI
- Developing AI literacy is an ongoing practice: follow institutional guidance, read model documentation, and engage with methodological debates in your own field.
References
- Edwards, S. V., Reeve, A. H., & Jonsson, J. E. (2023). Machine learning classification of birdsong syllables from multiple species. Scientific Reports, 13, 7824.
- Debus, M., Appel, M., Häfner, S., Sabourin, G., & Mermoz, S. (2025). Identification of deforestation drivers in Cameroon using deep learning with Landsat-8 satellite imagery. Remote Sensing of Environment, 317, 114546.
- Afriyie, J. K., Tawiah, K., Pels, W. A., Addai-Henne, S., Dwamena, H. A., Owiredu, E. O., Ayeh, S. A., & Eshun, J. (2023). A supervised machine learning algorithm for detecting and predicting fraud in credit card transactions. Decision Analytics Journal, 6, 100163.
- Gerlich, M. (2025). AI tools in society: Impacts on cognitive offloading and the future of critical thinking. Societies, 15(1), 6.
- de Vries-Gao, A. (2025). The carbon and water footprints of data centers and what this could mean for artificial intelligence. Patterns, 6, 101430.
- Li, P., Yang, J., Islam, M. A., & Ren, S. (2023). Making AI less “thirsty”: Uncovering and addressing the secret water footprint of AI models. Communications of the ACM.
- Luccioni, A. S., Jernite, Y., & Strubell, E. (2024). Power hungry processing: Watts driving the cost of AI deployment. Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency, 85–99
- Lannelongue, L., Grealey, J., Inouye, M., Green Algorithms: Quantifying the Carbon Footprint of Computation. Adv. Sci. 2021, 2100707. https://doi.org/10.1002/advs.202100707
- Electricity Maps
- Obermeyer, Z., Powers, B., Vogeli, C., & Mullainathan, S. (2019). Dissecting racial bias in an algorithm used to manage the health of populations. Science, 366(6464), 447-453.