Introduction to HPC Systems
Last updated on 2025-11-04 | Edit this page
Overview
Questions
- What is a High Performance Computing cluster?
- What is the difference between an HPC cluster and the cloud?
- How can an HPC cluster help me with my research?
- What HPC clusters are available to me and how do I get access to them?
Objectives
- Describe the purpose of an HPC system and what it does
- List the benefits of using an HPC system
- Identify how an HPC system could benefit you
- Summarise the typical arrangement of an HPC system’s components
- Differentiate between characteristics and features of HPC and cloud-based systems
- Summarise the capabilities of the NOCS HPC facilities
- Summarise the key capabilities of Iridis 6 and Iridis X for NOCS applications
- Summarise key capabilities of national HPC resources and how to access them
High Performance Computing

High Performance Computing (HPC) refers to the use of powerful computers and programming techniques to solve computationally intensive tasks. An HPC cluster, or supercomputer, is one which harnesses the aggregated power of groups of advanced computing systems. These high performance computers are grouped together in a network as a unified system, hence the name cluster. HPC clusters provide extremely high computational capabilities, significantly surpasssing that of a general personal computer.
Can you think of any computational research problems that could benefit from the aggregated computational power of High Performance Computing? Discuss it with your colleagues.
Here are some computation research examples where HPC could be of benefit: - A oceanography research student is modelling ocean circulation by processing seismic reflection datasets. They have thousands of these datasets - but each processing run takes an hour. Running the model on a laptop will take over a month! In this research problem, final results are calculated after all 1000 models have run, but typically only one model is run at a time (in serial) on the laptop. Since each of the 1000 runs is independent of all others, and given enough computers, it’s theoretically possible to run them all at once (in parallel).
The seismic reflection datasets are extremely large and the researcher is already finding it challenging to process the datasets on their computer. The researcher has just received datasets that are 10 times as large - analysing these larger datasets will certainly crash their computer. In this research problem, the calculations required might be impossible to speed up by adding more computers, but a computer with more memory would be required to analyse the much larger future data set.
An ocean modeller is using a numerical modelling system such as NEMO that supports parallel computation. While this option has not been used previously, moving from 2D to fully 3D ocean simulations has significantly increased the run time. In such models, calculations within each ocean subdomain are largely independent, allowing them to be solved simultaneously across processors while exchanging boundary information between adjacent regions. Because 3D simulations involve far more data and calculations, distributing the workload across multiple processors or computers connected via a shared network can substantially reduce runtime and make large-scale ocean simulations practical.
HPC clusters fundamentally perform simple numerical computations, but on an extremely large scale. In our examples we can see where HPC clusters excel, using hundreds or thousands of processors to complete a numerical task that would take a desktop or laptop days, months or years to complete. They can also tackle problems that are too large or complex for a PC to fit in their memory, such as modelling the ocean dynamics or the Earth’s climate.
High Performance Computing allows you as researchers to scale up your computational research and data processing, enabling you to do more research or to solve problems that would be infeasible to solve on your own computer.
HPC vs PC
Before we discuss High Performance Computing clusters in more detail let’s start with a computational resource we are all familiar with, the PC:
PC
 |
Your PC is your local computing resource, good for small computational tasks. It is flexible, easy to set-up and configure for new tasks, though it has limited computational resources. Let’s dissect what resources programs running on a laptop require:
|
If Our PC isnt Powerful Enough?

When the task to solve becomes too computationally heavy, the operations can be out-sourced from your local laptop or desktop to elsewhere.
Take for example the task to find the directions for your next conference. The capabilities of your laptop are typically not enough to calculate that route in real time, so you use a website, which in turn runs on a computer that is almost always a machine that is not in the same room as you are. Such a remote machine is generically called a server.
The internet made it possible for these data centers to be far remote from your laptop. The server itself has no direct display or input methods attached to it. But most importantly, it has much more storage, memory and compute capacity than your laptop will ever have. However, you still need a local device (laptop, workstation, mobile phone or tablet) to interact with this remote machine.
There is a direct parallel between this and running computational workloads on HPC clusters, in that you outsource computational tasks to a remote computer.
However there is a distinct difference between the “cloud” and an HPC cluster. What people call the cloud is mostly a web-service where you can rent such servers by providing your credit card details and by clicking together the specs of a remote resource. The cloud is a generic term commonly used to refer to remote computing resources of any kind – that is, any computers that you use but are not right in front of you. Cloud can refer to machines serving websites, providing shared storage, providing web services (such as e-mail or social media platforms), as well as more traditional “compute” resources.
HPC systems are more static and rigidly structured than cloud systems, and follow consistent patterns in how they’re deployed, whereas cloud infrastructures tend to be much more flexible and “user-led” in their configurations and provisioning.
HPC Cluster
If the computational task or analysis is too large or complex for a single server, larger agglomerations of servers are used. These HPC systems are known as supercomputers, or described as HPC clusters as they are made up of a cluster of computers, or compute nodes.
Distinct to the cloud, these clusters are networked together and share a common purpose to solve tasks that might otherwise be too big for any one computer. Each individual compute node is typically a lot more powerful than any PC - i.e. more memory, many more and faster CPU cores. However in parallel to the cloud you access HPC clusters remotely, through the internet.
The figure below shows the basic architecture of an HPC cluster.
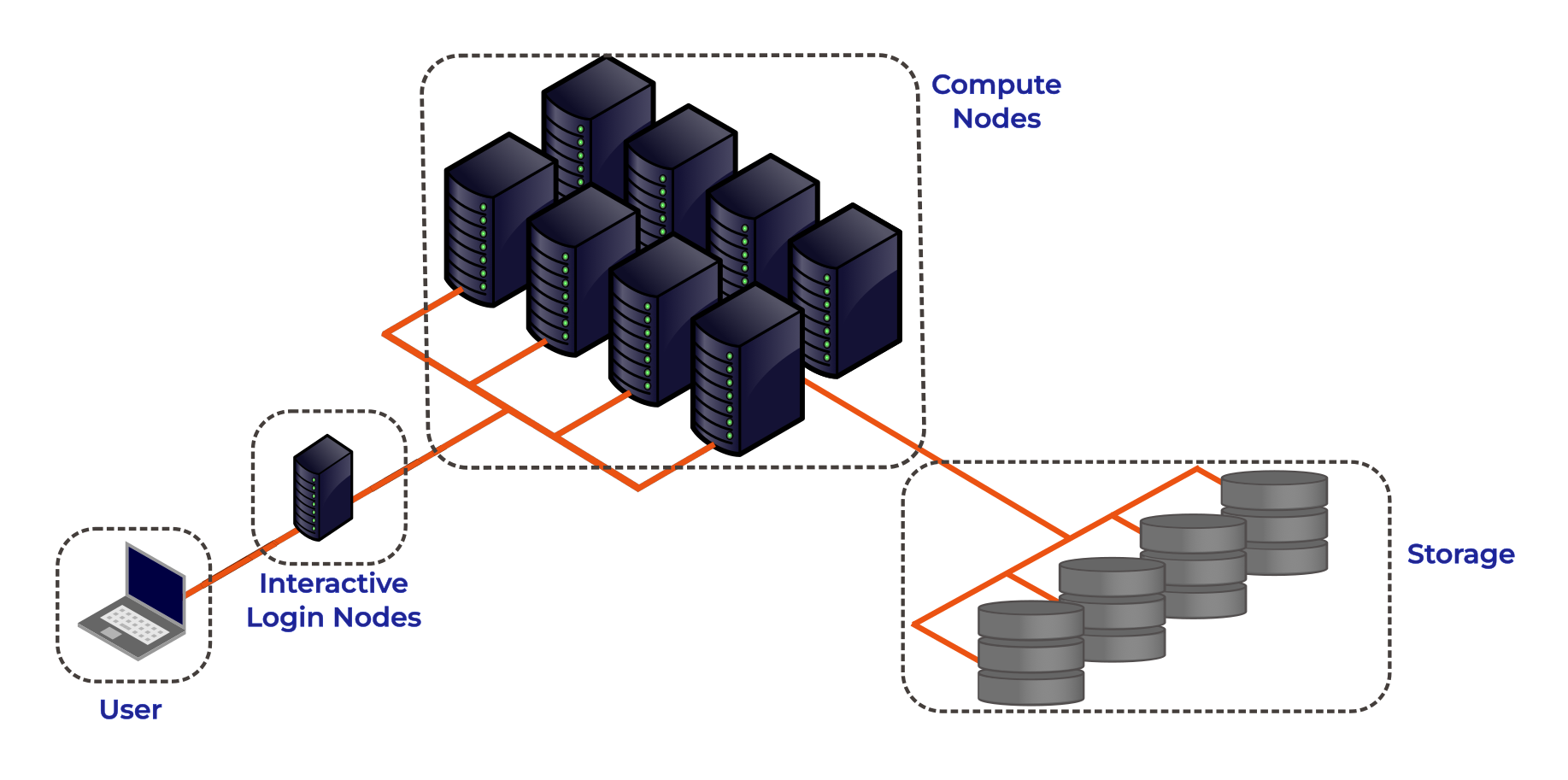
Lets go through each part of the figure:
Interactive Login Nodes
When you are given an account on an HPC cluster you will get some login credentials. Using these credentials you can remotely log-on to of the interactive login nodes from your local PC over the internet. There may be several login nodes, to make sure that all the users are not trying to access one single machine at the same time.
Once you have logged onto the login node you can now run HPC workloads, or jobs, on the HPC cluster. BUT you typically do not directly access the CPU/GPU cores that do the hard work. Supercomputers tend to operate in batch mode, where you submit your workload to a resource manager which places it in a queue (resource management and job submission will be discussed in more detail later). The login node is where you prepare and submit your HPC jobs to the queue to be scheduled to run.
The login nodes are used for:
- Interactive access point to the HPC resources.
- Transferring data onto/off the system.
- Compiling code and lightweight development tasks.
- Preparing and submitting HPC workload job scripts to the scheduler.
- Running short lightweight scripts for setup or testing.
- Not for heavy computation — they have limited resources, so running heavy computation here will affect other users!
Compute Nodes
The compute nodes are the core of the system, and provide the system resources to execute user jobs. They contain the thousands of processing units and memory, working in parallel, to run the HPC workloads. They are connected to one another through a high speed interconnect, so that the communication time between the processors on separate nodes impacts program run times as little as possible.
An HPC system may be made up of different types of compute node, for example a typical HPC system may have:
- Batch CPU Nodes: standard, general purpose, batch CPU nodes for executing parallel workloads. ( Tens/Hundreds of CPUs per node. Moderate RAM - hundreds of GBs)
- High-mem: nodes with similar CPUs to the standard nodes, but large amounts of memory (TBs of memory)
- GPU nodes: containing accelerators for highly parallel workloads e.g. AI training and inference, image processing and dense linear algebra.
- Interactive/Visualisation: nodes allowing users to run computationally intensive tasks interactively, such as data visualisation.
Storage
These nodes are equipped with large disk arrays to manage the vast amounts of data produced by HPC workloads. In most systems, multiple storage nodes and disk arrays are linked together to form a parallel file system, designed to handle the high input/output (I/O) demands of large-scale computations. Users do not access storage nodes directly; instead, their file systems are mounted on the login and compute nodes, allowing access to data across the cluster.
HPC vs PC
OK, now we have had a look at what makes up the basic components of an HPC cluster let’s summarise the key features and differences between your personal computer and an HPC cluster.
| Feature | Local PC | HPC Cluster |
|---|---|---|
| Hardware | Single standalone computer | Many interconnected compute nodes forming one system |
| Processors (CPU) | Few cores (4–16 typical) | Many CPUs per node; hundreds or thousands of cores total across the cluster |
| Memory (RAM) | Limited (8–128 GB) | Large aggregated memory (hundreds GB – several TB) |
| GPU (Accelerators) | Typically one consumer or workstation GPU (e.g., NVIDIA RTX) | Typically can have multiple high-end GPUs on GPU nodes (e.g., NVIDIA A100/H100), designed for massive parallel workloads |
| Storage | Local SSD/HDD; limited capacity | Shared large capacity high-speed parallel file system, and local SSD on compute nodes |
| Networking | Standard Ethernet; used mainly for internet or file sharing | High-speed interconnects for low-latency communication |
| Maintenance | User-maintained | Admin-maintained; centrally monitored and secured |
| Storage Access | Local file access only | Shared network storage accessible to all nodes |
| Typical Use Case | Small-scale data analysis, development, or prototyping | Large-scale simulations, data-intensive computing, ML/AI training |
| User Interaction | Direct, interactive sessions largely GUI based | Typically accessed through the command line; Batch jobs submitted to queue; limited interactive use |
The HPC Landscape
HPC facilities are divided into tiers, with larger HPC clusters being categorised in higher tiers.

In the UK there are three tiers, with an additional highest tier for continental systems:
- Tier 3: Local single institution supercomputers aimed towards researchers at one institution. At the University of Southampton we have the Iridis HPC cluster.
- Tier 2: Layer of HPC clusters that sit above the Tier 3, or University systems, and are larger or more specialised than most University systems. These are facilities that fill the gap between tier 3 and tier 1 facilities.
- Tier 1: Nationally leading HPC clusters.
- Tier 0: European facilities with petaflop systems, and the best across a continent. The Partnership for Advanced Computing in Europe (PRACE) provides access to the 8 Tier-0 systems in Europe.
Tier 3: Local HPC Clusters
Iridis 6 & Iridis X
The local tier 3 system at the University of Southampton is known as Iridis, which is comprised of two separate clusters known as Iridis 6 & and Iridis X.
Iridis 6 is the University’s CPU based HPC cluster, intended for running large parallel, multi-node, CPU based workloads. It comprised of 26,000+ AMD CPUs:
Iridis 6 Specification
- 134 Standard Compute Nodes
- Dual-socket AMD EPYC 9654 (2×96 cores) → 192 cores per node
- 750 GB RAM (≈650 GB usable)
- 6 Compute Nodes (EPYC 9684X)
- Dual-socket AMD EPYC 9684X (2×96 cores) → 192 cores per node
- 650 GB usable memory per node
- 4 High-Memory Nodes
- Dual-socket AMD EPYC 9654 (2×96 cores) → 192 cores per node
- 3 TB RAM (≈2.85 TB usable)
- 3 Login Nodes
- Dual-socket AMD EPYC 9334 (2×32 cores) → 64 cores per node
- 64 GB RAM limit and 2 CPU per-user limit on login nodes
Iridis X an hetereogeneous GPU cluster encompassing the University’s GPU offering:
Iridis X Specification
- AMD mi300x: 1 node — 128 CPU, 8× MI300X (192 GB each), 2.3 TB RAM
- NVIDIA H200:
- Quad h200: 4 nodes — 48 CPU, 4× H200 (141 GB each), 1.5 TB RAM per node
- Dual h200: 2 nodes — 48 CPU, 2× H200 (141 GB each), 768 GB RAM per node
- NVIDIA A100:
- 12 nodes — 48 CPU (Intel Xeon Gold), 2× A100 (80 GB each), 4.5 TB RAM per node
- 1 Maths Node (Can be scavenged when idle)
- NVIDIA L40: 1 node — 48 CPU, 8× L40 (48 GB each), 768 GB RAM
- NVIDIA L4: 2 nodes — 48 CPU, 8× L4 (24 GB each), 768 GB RAM per node
- CPU Only:
- AMD Dual AMD EPYC 7452: : 74 nodes (64 CPU), 240 GB RAM per node
- AMD Dual AMD EPYC 7502 Serial Partition : 16 nodes (64 CPU), 240 GB RAM per node
There is also departmental cluster within Iridis X, known as Swarm. It is for the use of the Electronics and Computer Science department, but it can be scavenged (i.e. used when idle). It contains:
- NVIDIA A100: 5 nodes — 96 CPU, 4× A100 SXM (80 GB each), 900 GB RAM per node
- NVIDIA H100: 2 nodes — 192 CPU, 8× H100 SXM (80 GB each), 1.9 TB RAM per node
You can find out more details about the system from the HPC Community Wiki, and to get access to the system there is a short application form to be filled in.
There is a team of HPC system adminstrators that look after Iridis, including supporting the installation and maintenence of the software you need. You can contact them through the HPC Community Teams.
Tier 2: Regional HPC Clusters
There are 9 EPSRC Tier 2 clusters in the UK. Access to the Tier 2 Facilities is free for academic researchers based in the UK, though getting on to any particular system may be dependent on your institution and the research you do. Typically getting compute time is through public access calls, such as the UKRI Access to High Performance Computing Facilities Call. Which is a “funding” call to get computational support for projects across the entire UK Research and Innovation (UKRI) remit. Each system may have also other routes to gaining access, such as including resources of the facility in research grant proposals.
 |
Cirrus (EPCC) — EPSRC Tier-2 HPC with 10,080-core SGI/HPE ICE XA system plus 36 GPU nodes (each with 4× NVIDIA V100). Free or purchasable academic access; industry access available. |
 |
Baskerville (University of Birmingham & partners) — Tier-2 EPSRC facility with 52 Lenovo Neptune servers, each with twin Intel IceLake CPUs and 4× NVIDIA A100 GPUs. Access via EPSRC HPC calls or the consortium. |
 |
Isambard 3 (GW4) — Tier-2 facility with a main cluster containing 384 NVIDIA Grace CPU Superchips, 72 cores per socket, along with MACS (Multi-Architecture Comparison System) containing multiple different examples of architecture for testing/benchmarking/development. Free for EPSRC-domain academics; purchasable and industry access available. |
 |
CSD3 (Cambridge) — Data-centric Tier-2 HPC for simulation and analysis, operated across multiple institutions. Access through EPSRC calls for academics and industry users. |
 |
Sulis (HPC Midlands+) — Tier-2 HPC for ensemble and high-throughput workflows using containerisation for scalable computing. Access via EPSRC calls or the Midlands+ consortium. |
 |
Jade (Joint Academic Data Science Endeavour) — EPSRC Tier-2 deep learning system built on NVIDIA DGX-1 with 8× Tesla P100 GPUs linked by NVLink. Free for EPSRC academics; paid and industry access available. |
 |
MMM Hub (Materials and Molecular Modelling Hub) — Tier-2 supercomputing facility for materials and molecular modelling, led by UCL with partners in the Thomas Young Centre and SES Consortium. Available UK-wide. |
 |
NI-HPC — “Kelvin2” Tier-2 cluster supporting neuroscience, chemistry, and precision medicine with 60×128-core AMD nodes, 4 hi-memory nodes, and 32× NVIDIA V100s. Fast-track access. |
 |
Bede at N8 CIR — EPSRC Tier-2 HPC with 32 IBM POWER9 nodes (each 4× NVIDIA V100 GPUs) plus 4 NVIDIA T4 nodes for AI inference. Access via EPSRC calls or N8 partner universities. |
Tier 1: National HPC Systems
There are four National HPC facilities in the UK, each of which have different architecture and will be suitable for different computational research problems.
 |
ARCHER2 — the UK’s national supercomputing service offers a capability resource for running very large parallel jobs. Based around an HPE Cray EX supercomputing system with an estimated peak performance of 28 PFLOP/s, the machine will have 5,860 compute nodes, each with dual AMD EPYC Zen2 (Rome) 64 core CPUs at 2.2GHz, giving 750,080 cores in total. The service includes a service desk staffed by HPC experts from EPCC with support from HPE Cray. Access is free at point of use for academic researchers working in the EPSRC and NERC domains. Users will also be able to purchase access at a variety of rates. |
 |
DiRAC — HPC for particle physics and astronomy, comprising multiple architectures. Including: Data Intensive Cambridge - DIRAC (746,496 GPU Cores), Data Intensive Leicester - DIAL (40,288 CPU cores), Extreme Scaling Edinburgh - ES (4,921,344 GPU Cores), Memory Intensive Durham - DI (80,240 CPU Cores with 731TB memory). Free for STFC-domain academics; purchasable and industry access available. |
|
|
Isambard AI — As well as the Isambard 3 tier 2 system the GW4 also manages Isambard-AI: National AI Research Resource (AIRR), a tier 1 AI HPC system aimed at supporting AI and GPU enabled computational research. It is composed of 5448 GH200 Grace Hopper superchips containing one Grace CPU and one Hopper H100 GPU. It is ranked 11th in the TOP500 list of the fastest supercomputers in the world. |
 |
Dawn — The AI Research Resource (AIRR) also includes Dawn, a tier 1 AI HPC cluster aimed at supporting AI and GPU enabled computational research. The Cambridge Dawn facility is made up of 1,024 Intel Data Centre GPU Max 1550 GPUs. |
Access to the National Facilities is through public access calls:
- ARCHER2: access for UK acadmeics is typically through the UKRI Access to High Performance Computing Facilities Call.
- AIRR (Isambard-AI & DAWN): access for UK academics is typically through the AIRR Gateway route, offering up to 10,000 GPU hours, designed for researchers from academia, industry, or other UK organisations.
- DiRAC: access for UK academics is typically through the STFC’s Resource Allocation Committee calls.
- High Performance Computing (HPC) combines many powerful computers (nodes) into clusters that work together to solve large or complex computational problems faster than a personal computer.
- HPC is essential when problems are too big, data too large, or computations too slow for a single machine.
- HPC facilities in the UK are divided into tiers: the largest systems categorised in higher tiers. The University of Southampton’s HPC system is a local tier 3 facility and you can get access to use it.