Introduction to Programmatic Parallelism
Last updated on 2025-10-22 | Edit this page
Overview
Questions
- What is parallelisation and how does it improve performance?
- What are the different types of parallelisation?
- Why does synchronisation matter?
Objectives
- Describe the concept of parallelisation and its significance in improving performance
- Differentiate between parallelising programs via processes and threads
- Compare and contrast the operation and benefits of shared and distributed memory systems
- Define a race condition and how to avoid them
Parallel programming has been important to (scientific) computing for decades as a way to decrease how long a piece of code takes to run making more complex computations possible, such as in climate modelling, pharmaceutical development, aircraft design, AI and machine learning, and etc. Without parallelisation, these computations which would take years to finish can instead be completed in hours or days! In this episode, we will cover the foundational concepts of parallel programming. But, before we get into the nitty-gritty details of parallelisation frameworks and techniques, let’s first familiarise ourselves with the key ideas behind parallel programming.
What is parallelisation?
At some point you, or someone you know, has probably asked “how can I make my code faster?” The answer to this question will depend on the code, but there are a few approaches you might try:
- Optimise the code.
- Move the computationally demanding parts of the code from a slower, interpreted language, such as Python, to a faster, compiled language such as C, C++ or Fortran.
- Use a different theoretical/computational or approximate method which requires less computation.
All of these reduce the total amount of work the processor does. Parallelisation takes a different approach: splitting the workload across multiple processing units such as central processing units (CPUs) or graphics processing units (GPUs). Each processing unit works on a smaller batch of work simultaneously. Instead of reducing the amount of work to be done by, e.g. optimising our code, we instead have multiple processors working on the task at the same time.
Sequential vs. parallel computing
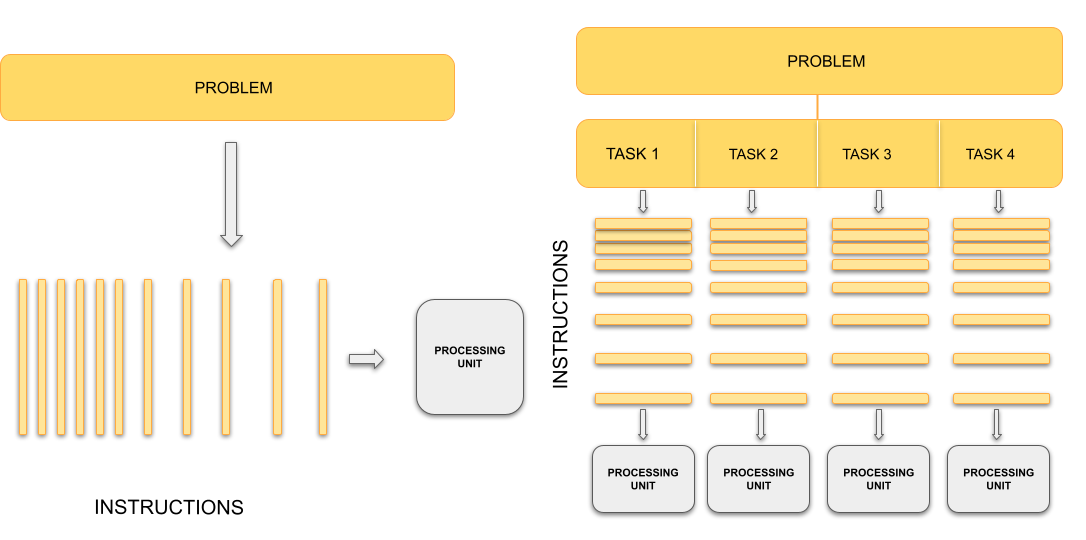
Traditionally, computers execute one instruction at a time, in the sequence defined by the code you have written. In other words, your code is compiled into a series of instructions which are executed one after another. We call this serial execution.
With parallel computing, multiple instructions, from the same program, are carried out at the same time on different processing units. This means more work is being done at once, so we get the results quicker than if we were running the same set of instructions sequentially on a single processor. The process of changing sequential code to parallel code is called parallelisation.
Painting a room
Parallel computing means dividing a job into tasks that can run at the same time. Imagine painting four walls in a room. The problem is painting the room. The tasks are painting each wall. The tasks are independent, you don’t need to finish one wall before starting another.
If there is only one painter, they must work on one wall at a time. With one painter, painting the walls is sequential, because they paint one wall at the time. But since each wall is independent, the painter can switch between painting them in any order. This is concurrent work, where they are making progress on multiple walls over time, but not simultaneously.
With two or more painters, walls can be painted at the same time. This is parallel work, because the painters are making painting the room by painting multiple walls at the same time.
In this analogy, the painters represent CPU cores. The number of cores limits how many tasks can run in parallel. Even if there are many tasks, only as many can progress simultaneously as there are cores. Managing many tasks with fewer cores is called concurrency.
Key parallelisation concepts
There is, unfortunately, more to parallelisation than simply dividing work across multiple processors. Whilst the idea of splitting tasks to achieve faster results is conceptually simple, the practical implementation is more complex. Adding additional CPU cores raises new issues:
- If there are two cores, they might share the same RAM (shared memory) or each have their own dedicated RAM (private memory). This distinction affects how data can be accessed and shared between processors.
- In a shared memory setup, what happens if two cores try to read or write the same memory location at the same time? This can cause a race condition, where the outcome depends on the timing of operations.
- How do we divide and distribute the workload evenly among the CPU cores? Dividing the workload unevenly will result in inefficient parallelisation.
- How will the cores exchange data and coordinate their actions? Additional mechanisms are required to enable this.
- After the tasks are complete, where should the final results be stored? Should they remain in the memory of one CPU core, be copied to a shared memory area, or written to disk? Additionally, which core handles producing the output?
To answer these questions, we need to understand what a process and what a thread is, how they are different, and how they interact with the computer’s resources (memory, file system, etc.).
Processes
A process is an individual running instance of a software program. Each process operates independently and possesses its own set of resources, such as memory space and open files, managed by the operating system. Because of this separation, data in one processes is typically isolated and cannot be directly accessed by another process.

One approach to achieve parallel execution is by running multiple coordinated processes at the same time. But what if one processes needs information from another processes? Since processes are isolated and have private memory spaces, information has to be explicitly communicated by the programmer between processes. This is the role of parallel programming frameworks and libraries such as MPI (Message Passing Interface). MPI provides a standardised library of functions that allow processes to exchange messages, coordinate tasks and collectively work on a problem together.
This style of parallelisation is the dominant form of parallelisation on HPC systems. By combining MPI with a cluster’s job scheduler, it is possible to launch and coordinate processes across many compute nodes. Instead of having access to just a single CPU or computer, our code can now use thousands or even tens of thousands of CPUs across many computers which are connected together.
Threads
A thread is a unit of execution which exists within a process. Unlike processes, threads share their parent process’ resources, including memory and open files, so they can directly read and write the same memory space. This shared access means threads can exchange data faster, since they do not have to communicate it between them.

By running multiple threads, over multiple CPU cores, a program can coordinate for each thread to work on their own task(s). For example, one thread may handle input/output whilst other threads perform some number crunching, or multiple threads might process different parts of a dataset simultaneously.
A major advantage of using threads is their relative ease of use compared to processes. With frameworks such as OpenMP), which provides a set of compiler extensions and libraries for paralleling code using threads, existing code can be adapted for parallel execution with, often, relatively small changes. Because threads share a memory space, there is no need for explicit message-passing mechanisms (as required with processes). However, this shared memory model introduces the possibility of race conditions, where two or more threads attempt to update the same data at once. Careful synchronisation is therefore required. It is important to note, however, that threads are confined to a single process and therefore to a single computer. Programs which are parallelised using threads cannot span across compute nodes in a cluster.
Shared vs distributed memory parallelisation
When writing parallel programs, a key distinction is whether there is a single shared memory space or if there are multiple private memory spaces. These two models are called shared memory and distributed memory.
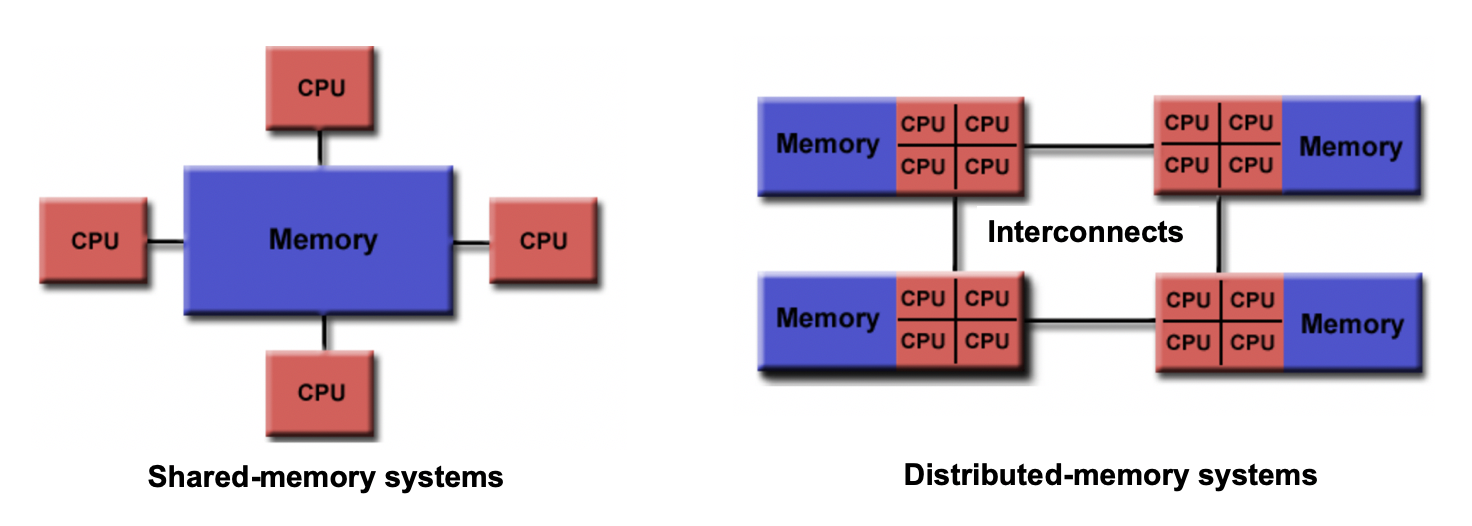
In a shared memory system, all processors (or cores) can directly access and modify the same pool of memory. Changes made by one processor are immediately visible to the others. This model aligns naturally with parallelisation using threads, which exist within a single process and share the parent process’ memory. However, shared memory has limitations: if multiple threads try to update the same data simultaneously, race conditions can occur. Correct results require careful synchronisation. Programming models such as OpenMP (Open Multi-Processing) provide mechanisms to divide work among threads and synchronise access to shared data. In general, shared memory approaches are generally limited to the cores within a single computer or node. The advantage of shared memory is its simplicity, making it easier to implement and debug. The main disadvantage is limited scalability, as performance gains are constrained by the number of cores in a single node and the complexity of synchronisation.
In a distributed memory system, each processor has its own private memory. Data cannot be accessed directly by other processors, it must be explicitly sent and received. This model aligns with parallelisation using processes which each have their own private memory space. Communication between processes is typically handled using libraries such as MPI. Distributed memory programming requires more effort than shared memory, but it enables programs to scale across multiple nodes in a cluster. The advantage of distributed memory is its high scalability, allowing computations across thousands of nodes. The disadvantages include increased programming complexity and additional overheads required for communication information, as data must be explicitly exchanged between processes (private memory spaces).
The differences can be summarised:
- Accessibility: Shared memory allows direct access to a common memory space. Distributed memory requires explicit communication for data exchange.
- Memory scope: Shared memory provides a global pool, while distributed memory isolates each processor’s memory.
- Consistency: In shared memory, changes are immediately visible to all cores. In distributed memory, explicit synchronisation is needed to keep results consistent.
- Scalability: Shared memory is limited to one node. Distributed memory scales to thousands of nodes.
- Programming complexity: Shared memory models are simpler to use but harder to scale. Distributed memory models scale well but require more explicit programming.
- Advantages/Disadvantages: Shared memory is easier to program , but is limited in scale and prone to synchronisation issues. Distributed memory scales to more cores, but is more complex and requires explicit data communication.
In sophisticated applications, a hybrid approach is used which combines using processes to spread the workload across multiple nodes, but uses shared-memory parallelisation on a node. This takes advantage of the scalability of distributed memory, and the efficiency of using shared-memory with threads.
Synchronisation and race conditions
Synchronisation ensures that processing units can coordinate their actions correctly, particularly when threads are accessing or modifying shared data. Without proper synchronisation, multiple threads, for example, might attempt to update the same variable simultaneously, leading to unpredictable results known as a race condition.
In a shared memory system, synchronisation mechanisms such as barriers, locks, and atomic operations are used to control access to shared data and to coordinate work. A barrier ensures that threads have reached a certain point before continuing, while locks prevent sections of code from being executed simultaneously, preventing race conditions. Atomic operations allow individual updates to shared variables without interference, meaning only one thread can update a variable at once. Proper use of these mechanisms ensures code correctness, maintaining consistent and valid results.
In distributed memory systems, synchronisation is achieved by coordinating communication between processes to order the workload and manage data dependencies. Even though processes have their own private memory space, race conditions can still occur if two processes write to the same file. Effective synchronisation, whether with threads or processes, is crucial for ensuring that parallel programs produce correct, reproducible results.
Organising the painters
Imagine several painters working on the same set of walls. If each painter tries to paint the same wall at the same time without coordinating, they might overwrite each other’s work creating a mess. This is like a race condition in parallel programming, where there is simultaneous memory access modifying the same data.
To avoid this, painters might take turns for the shared wall, or divide walls so each painter works independently. In programming, mechanisms like barriers or atomic operations perform the same role: they synchronise access to shared resources.
This coordination ensures that all parts of the task progress in the right order, whether you are updating a shared variable, writing results to disk, or aggregating data.
- Parallelisation speeds up computation by dividing work across multiple processing units.
- Processes use private memory and communicate information explicitly between them (distributed memory, e.g. MPI).
- Threads share memory within a process and require synchronisation to prevent race conditions.
- Shared memory parallelisation is simpler but limited in scale. Distributed memory scales better, but is more complex.