Introduction to AI Coding IDE Tools
Last updated on 2026-02-10 | Edit this page
Overview
Questions
- Where does generative AI fit within the broader historical and technical landscape of AI systems?
- How do large language models generate text, code, or explanations without understanding meaning in a human sense?
- How can an AI coding assistant help development within an IDE?
- What are the mechanisms by which IDE AI assistants provide help?
- How should I sensibly and responsibly include AI coding assistants in my development workflow?
- What are the limitations of a free Copilot account?
- What is GitHub Copilot?
- Which AI models are available within Copilot?
Objectives
- Describe where ChatGPT and similar large language models fit within the broader AI landscape.
- List the three main categories of AI systems.
- Explain, at a conceptual level, what generative AI and ChatGPT are.
- Summarize the primary functions and intended use cases of common AI coding assistants.
- Describe some common tasks undertaken by an IDE coding assistant.
- Describe a responsible approach to using IDE coding assistants in development.
- Describe how GitHub Copilot integrates with Visual Studio Code.
- Describe the lifecycle of a Copilot request and how it uses data.
- Describe the different built-in models and their specialisms and tradeoffs.
- List the limitations of the free pricing tier of GitHub Copilot.
Introduction
Software is critical to research - the Software Sustainability Institute’s UK Research Software Survey found that more than 92% of academics use research software, and 56% write their own code. A study also conducted by the Institute also found an exponential increase in the prevalence of software-related terms in publications between 2000-2017.
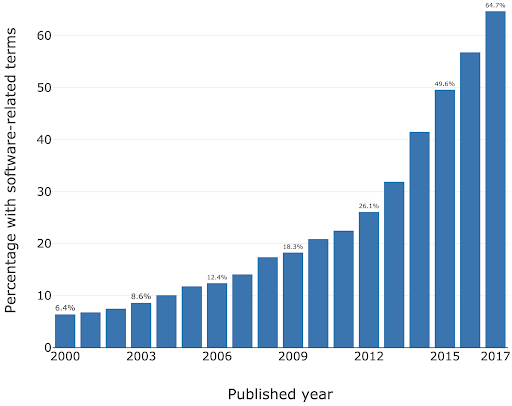
As a specific institutional example, when researchers were asked “how important is research software to your work?” in a software study conducted at the University of Southampton, 73% of respondents indicated that it was “Vital”.
For many researchers, writing code for data analysis or software development can be boring, frustrating, or intimidating. Most researchers would rather be thinking about and researching their subject matter rather than spending lots of time learning a programming language and writing code. Therefore, with easy access to AI tools, it can be very tempting to ask AI to write your research code for you.

This course aims to:
- Recap/provide a light introduction for how to use Microsoft Visual Studio Code
- Provide a working AI-supported environment within the Visual Studio Code Integrated Development Environment
- Demonstrate the fundamentals of how to use Copilot within Visual Studio Code to expedite research software development
- Introduce practical ways to mitigate the risks of using AI coding assistants within day-to-day software development
Current Landscape of AI
In recent years, one particular type of AI system, generative AI, has dominated public and professional interaction with artificial intelligence. While highly visible, generative AI represents only one approach within a much broader AI landscape.
At a high level, today’s AI systems can be grouped into three broad categories:
1. Rule-Based and Decision Systems
These systems operate using explicitly defined rules, logic, or constraints. Their behaviour is deterministic and transparent, which makes them reliable in stable, well-defined environments. Rule-based systems are still widely used in areas such as compliance, governance, and safety-critical decision-making. However, they are limited in their ability to handle ambiguity, novelty, or rapidly changing conditions.
A laboratory safety interlock is an example of a rule-based system. It monitors the state of critical variables, such as door positions, pressure levels, temperature, radiation shielding, or airflow, and allows an action only if all safety conditions are met. For example, a high-power laser system may be physically prevented from firing unless the enclosure door is closed, warning lights are active, and emergency stops are disengaged. If any condition is violated, the system immediately shuts down or blocks operation.
These systems are deterministic and transparent, in other words the same inputs always lead to the same outcome and the rules governing behaviour are explicitly defined. Unlike learning-based AI systems, laboratory safety interlocks do not adapt or infer, they exist to enforce safety rules reliably, even in the presence of human error.
2. Predictive and Analytical Systems
These systems learn patterns from data to make predictions, classifications, or risk estimates. Rather than following fixed rules, they use statistical models to answer questions such as ‘What category does this belong to?’ or ‘How likely is this outcome?’ Predictive AI systems are common in research and operational settings, including data analysis, diagnostics, and forecasting. Their outputs support decisions but do not create new content.
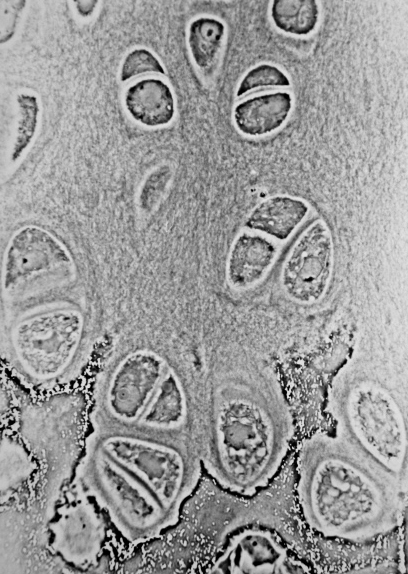
One example of a predictive AI system is a machine-learning model trained to automatically label features in microscope images, such as identifying specific cell types or structures.
The model learns from large sets of images that have been annotated by experts, using statistical patterns like shape, texture, and intensity to distinguish between categories. Once trained, it can rapidly classify new images, allowing researchers to analyse large datasets more efficiently and consistently than manual methods.
The system provides probabilities, rather than definitive answers, as outputs and does not generate new content or biological insight. The results must be validated and interpreted by researchers, as the model’s performance depends heavily on the quality of the training data and imaging conditions.
3. Generative Systems
Generative AI systems are designed to produce new outputs that resemble the data on which they were trained. This includes generating text, code, images, or other media. The current AI systems that we are familiar with, such as ChatGPT, fall into this category. These systems are optimised for producing fluent and contextually appropriate responses, not for verifying truth or making authoritative decisions.
Some examples of generative AI uses:
- The language learning app Duolingo uses generative AI to explain mistakes and practice conversations. The features are part of a new subscription tier called “Duolingo Max”.
- The education website Khan Academy is using generative AI for their tutoring chatbot called “Khanmigo”
- An app called Be My Eyes helps people with visual impairments to identify objects and navigate their surroundings, by using the image recognition capabilities of GPT-4.

Most AI systems in use today are narrow, task-specific tools. Some are designed to enforce rules, others to analyse data and make predictions, and an increasingly visible group, generative systems, are designed to produce new content. Generative AI systems are powerful and influential, but they are not representative of AI as a whole. Hopefully, understanding these broad categories helps us to set appropriate expectations for AI and prepares us to examine generative AI in more detail.
| AI System Type | What the system does | Strengths | Limitations |
|---|---|---|---|
| Rule-Based & Decision Systems | Follows clearly defined rules to allow, block, or trigger actions | Predictable and transparent; behaves the same way every time; well suited to safety-critical or regulated settings | Cannot adapt to new situations or handle uncertainty |
| Predictive & Analytical Systems | Uses data to estimate categories, trends, or likelihoods | Can analyse large datasets efficiently; supports consistent analysis and forecasting | Results depend on data quality; outputs are probabilities, not final answers |
| Generative Systems | Creates new text, code, images, or other content | Flexible and easy to interact with; useful for drafting, coding, and exploring ideas | Outputs can sound confident but be incomplete or wrong |
Human Oversight Across AI Types
Human responsibility increases from rule-based to predictive to generative systems because more judgment, interpretation, and accountability must be carried by people rather than the system itself.
- Rule-based systems behave exactly as specified and therefore the responsibility is mostly in system design, not in day-to-day interpretation.
- Predictive systems give estimates, not decisions and the responsibility lies with humans for interpretation and validation.
- Generative systems require the highest human responsibility at the point of use. For example, when a researcher uses generative AI to draft text, summarise literature, or generate code, the responsibility for correctness remains entirely with the human.
Demystifying Generative AI
What Is GPT?
The model of generative AI that has been widespread in recent years is GPT. An AI model that can produce text that reads as coherent and context-aware, such as explanations, summaries, or responses to questions.
ChatGPT is an application built on top of GPT models. It provides a user-friendly, conversational interface to interact with the GPT model. ChatGPT is one of many tools that use GPT.
GPT is also integrated into software products such as Microsoft’s Copilot, search engines, and coding environments.
GPT stands for Generative Pre-trained Transformer:
- Generative: GPT is designed to generate new content. Rather than retrieving fixed answers from a database, it produces original outputs, such as text or code.
- Pre-trained: it is trained on vast amounts of data before deployment.
- Transformer: this refers to the internal design of the neural network that helps the system keep track of context across longer pieces of text.
Understanding Large Language Models
Systems like GPT belong to a group called Large Language Models (LLMs). An LLM is a program that learns how language works by analysing very large collections of text. It does not store facts in a database or follow pre-programmed rules. Instead, it learns patterns in how words, sentences, and ideas tend to appear together.
LLMs are built using neural networks. In this context, a neural network provides the underlying learning machinery that allows the system to absorb information from large amounts of text and improve its predictions over time.
What is a neural network?
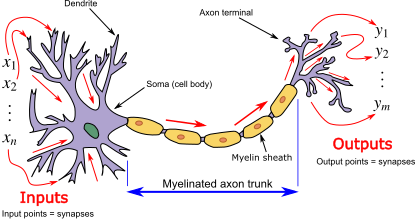
A neural network is a type of computational model inspired by how the human brain processes information. The name comes from its loose resemblance to brain cells (called neurons), but it is not a biological model of the brain.
Instead, a neural network is built from many simple processing units, called neurons, that pass information to one another in stages. Each neuron receives inputs, applies a simple rule to transform them, and then passes the result forward. By stacking many of these stages on top of each other, the system can learn complex patterns in data.
Learning in a neural network happens gradually as the network adjusts how strongly the neurons influence each other so that its outputs become more accurate over time.

What is a transformer?
A transformer is a type of neural network architecture designed specifically to work with sequences, such as sentences, paragraphs, or lines of code. Its key strength is the ability to consider context, that is, how different parts of a sequence relate to one another, when processing or generating information.
Traditional language-processing systems handled text one word at a time, in order. This made it difficult for them to keep track of long-range relationships, such as how a word at the start of a sentence relates to one at the end. Transformers address this limitation by processing all parts of a text sequence simultaneously, allowing the model to identify patterns and relationships across an entire passage at once.
The central mechanism that enables this is called attention. Attention allows the model to assign different levels of importance to different words in a sentence depending on the context. For example, when interpreting the meaning of a pronoun such as “it,” the transformer can look back across the sentence or paragraph to determine which earlier word is most relevant. This makes the model far more effective at handling complex language structures. For example, consider the sentence “The cat ate the mouse because it was hungry.” Attention helps the model see that “it” refers to “the cat”, not “the mouse,” by focusing on the most relevant word in the sentence.
In practical terms, the transformer architecture is what enables systems like GPT to produce fluent, context-aware text, maintain coherence over long responses, and adapt their output to different tasks using the same underlying model. However, despite their apparent sophistication, transformers do not reason or understand language; they identify and reproduce patterns based on statistical relationships learned during training.
GPT generates content token by token, rather than producing an entire sentence all at once. A token can be a word, part of a word, or a punctuation mark.
This sequential token generation allows GPT to produce coherent and contextually relevant text because each new token is generated in the context of all previous tokens. It’s like writing a sentence one word at a time, making sure each word fits with everything written before it.
When you enter a prompt into GPT:
- The model looks at the input text (the prompt) and splits it into tokens.
- It predicts the probability of each possible next token based on all previous tokens.
- A token is chosen based on the model’s predicted probabilities. Either the most likely token is selected, or one is sampled from the distribution of probable tokens to allow more varied or creative outputs.
- The token is added to the growing output sequence.
- Steps 2–4 repeat until the model produces a complete response.
- The tokens are decoded back into human-readable text.
As you can now understand, GPT doesn’t simply retrieve pre-written sentences, but instead builds content step by step and this is why it can generate such flexible and novel outputs.
What is a token?
A token is the basic unit of text that a GPT model
processes and generates. Tokens are not always whole words. They may be
a full word (e.g. data), part of a word
(e.g. clean + ed), numbers, symbols, or
punctuation (e.g. ., ,, ().
Consider the sentence:
“The dataset was cleaned.”
Internally, the model might split this into tokens such
as:The| data | set |
was | clean | ed |
.
Large language models do not decide how to split words dynamically. Instead, tokenisation is fixed in advance by a tokeniser created before training. Most GPT-style models use subword tokenisation methods such as Byte Pair Encoding (BPE) or similar approaches, which merge frequently occurring character sequences until a fixed vocabulary size is reached.
Common words are typically single tokens (e.g. data),
while less common or more complex words are split into subword tokens
(e.g. token + isation). This allows the model
to handle new or rare words by recombining familiar pieces rather than
requiring a unique token for every word.
Tokens do not necessarily align with meaning or syllables because tokenisation is statistical rather than linguistic. This explains why prompts that seem similar to us humans can produce very different outputs.
Understanding tokenisation allows us to appreciate a key limitation of GPT: the model optimises for what is likely to follow, not for what is correct, so early token-level errors can influence the rest of the response.
How a GPT Model is Trained
- Data collection - A large amount of text is gathered to train the AI model on.
- Model architecture design - The neural network architecture is designed to best suit the purpose of the AI
- Pre-training - The AI model is trained on the collected text.
- Fine-tuning - Further training the model on specific datasets and tasks related to its purpose e.g. if it is going to be a code assistant it will be trained on tasks related to code generation.
- Alignment – Guide the model so that its outputs are helpful, safe, and in line with human intentions. This often involves human feedback to encourage responses that are accurate, reliable, and appropriate.
- Evaluation and iteration - Testing the AI in a variety of use cases, getting feedback and iterating the model architecture to improve performance.

Overview of AI tools that can support research coding
AI-Assisted Coding Tools
ChatGPT – A conversational large language model by OpenAI that can generate code, explain programming concepts, assist with debugging, and support data analysis workflows.
GitHub Copilot – AI-powered coding assistant integrated into code editors, suggesting code completions, functions, and boilerplate across multiple programming languages.
Google Gemini – Google’s AI platform for research and coding assistance, capable of generating code, providing explanations, and supporting data analysis and workflow tasks.
Claude – A conversational AI by Anthropic designed to assist with coding, writing, and research tasks, providing explanations, summaries, and code generation support.
Microsoft Copilot – Integrated into Microsoft tools like Word, Excel, and Visual Studio, this AI assistant helps with code generation, data analysis, and workflow automation.
Within the course, we’ll be Copilot with a selection of its integrated AI models (ChatGPT and Claude) as the vehicles to illustrate the concepts and demonstrate how to use these tools.
Levels of AI-Assisted Coding
The Oxford AI Competency Centre suggest thinking about AI-Assisted Coding as existing in four levels of differing complexity and capability:
Level 1: Code Snippets (Copy and Paste) A Large Language Model inside a chatbot generates code that you copy and paste into files or environments you manage yourself. Examples: ChatGPT, Claude, Gemini, GitHub Copilot Chat
Level 2: Canvas and Artifacts (Integrated Execution) LLM writes code inside a chatbot and immediately runs it within the chat interface, creating interactive applications you can use and modify in real-time. Examples: Google Gemini, Claude Artifacts, ChatGPT Canvas
Level 3: Agentic App Builders (Full Application Development) LLM-powered services that plan and execute the entire development process, from concept to deployed application, handling multiple files, frameworks, and deployment automatically. Examples: Lovable, Bolt, v0 by Vercel, Google AI Studio
Level 4: Agentic IDEs (Professional Development) AI-powered development environments that assist with complex, multi-file projects, handling entire codebases, version control, and sophisticated development workflows. Examples: Cursor, GitHub Copilot, Claude Code, Google Colab
This intermediate course addresses working within Level 4, using Microsoft Visual Studio Code (VSCode) and Copilot.
Which tools are most commonly used by researchers?
In a study of 868 scientists who code as part of their research, ChatGPT was by far the most common tool used to assist with research coding, used by 64% of participants, followed by GitHub Copilot, used by 12% of participants.
(O’Brien, G., Parker, A., Eisty, N., & Carver, J. (2025). More code, less validation: Risk factors for over-reliance on AI coding tools among scientists. arXiv preprint arXiv:2512.19644.)
Using AI Coding Assistants in Integrated Development Environments (IDEs)
Generative AI has the potential to transform how researchers work with code, and with the integration of such capability within common IDEs, such as Visual Studio Code, provide the coding researcher with powerful tools to modify, expand and otherwise work with code. But this potential needs to be tempered with critical thinking and a healthy degree of skepticism.

Common Tasks and Features
AI coding assistants in IDEs (such as GitHub Copilot) provide a bewildering array of support for various tasks. For code editing, these include:
- Code completion and generation – suggests and generates code snippets based on context, reducing time spent on boilerplate and repetitive code
- Function and method suggestions – proposes complete function implementations based on function signatures and docstrings
- Refactoring support – suggestions for improving code structure and readability
At a higher level, they can also provide:
- Code explanation – explains how existing code works, helping researchers understand unfamiliar code or learn new programming patterns
- Debugging assistance – identifies potential bugs and suggests fixes for problematic code
- Documentation generation – automatically generates comments, docstrings, and README content
- Test generation – creates unit tests for existing code to improve code reliability
- Language/framework translation – converts code between programming languages and frameworks
Such tools even have the capability to assist with writing new code, helping to structure projects and write new functionality by generating code based on high-level descriptions, function signatures, and requirements. These initial implementations are then reviewed and refined by developers.
Benefits and Risks
AI coding assistants offer several key benefits to research software development. They can accelerate development by reducing time spent on routine coding tasks, allowing researchers to focus on domain-specific problems. Plus, for those new to a programming language, these tools help lower the learning curve and enable faster productivity. The suggestions and examples provided by AI assistants may also encourage better coding practices and improve overall code quality. Additionally, they make it easier to maintain clear and comprehensive documentation, supporting long-term code maintainability.
However, they also introduce a number of significant risks:
- Correctness and Validation - generative systems optimize for likelihood, not correctness. AI-generated code can sound confident but be incomplete, incorrect, or insecure. Researchers remain fully responsible for validating outputs.
- Limited explanation - unlike a standalone AI like ChatGPT, IDE-integrated AI often provides suggestions without detailed reasoning. This can reduce researchers’ understanding of AI-generated code
- Potential over-reliance - it can be very tempting to accept AI code suggestions that appear to work, without fully understanding them, and this can lead to errors or misunderstandings about what your code does.
- Privacy and security risks - the AI may send code snippets to cloud services for processing. Sensitive data or unpublished research could be exposed if this is not carefully managed.
- Context and Edge Cases – AI assistants may miss domain-specific requirements, edge cases, or research-specific constraints that are critical for correctness.
- Code Quality - generated code may work but be inefficient, poorly structured, or violate best practices, degrading long-term maintainability.
There are also a number of tangential non-coding risks we should consider. One of these is vendor lock-in: as the perceived value of a particular vendor’s AI tool increases, so does the risk of dependence on that particular vendor’s tool. This can make switching tools difficult and leaving users at greater risk of service price increases and at the mercy of that vendor’s product roadmap, which may not align with the goals of the user. Secondly, depending on the training data used (e.g. codebases, best practice articles, etc.), biases may be introduced that favour particular technical tools and approaches which are not optimal or even sensible choices for a project. Plus, even Microsoft acknowledges that “The language, image, and audio models that underly the Copilot experience may include training data that can reflect societal biases, which in turn can potentially cause Copilot to behave in ways that are perceived as unfair, unreliable, or offensive.” These may include the reinforcing of negative stereotypes, over or under-representation of specific groups of people, even inappropriate or offensive content, and variable performance across different spoken languages.
Research software produces results that inform publications, policy, and further research. Unlike commercial software where bugs typically cause inconvenience, errors in research code can invalidate findings, waste resources, introduce unwanted biases, and compromise scientific integrity. AI tools optimize for likelihood, not correctness, so again, as responsible researchers, we must scrutinise AI generative responses.
The Cautionary Tale of Replit’s use of AI
There are an increasing number of AI cautionary tales being reported in the media.
A particularly disturbing event at Replit was reported in June 2025. Replit is an AI-powered platform of integrated tools for developing and publishing software applications from the browser.
According to the account, the AI coding assistant behaved unpredictably during development, allegedly wiping a database, altering code against explicit instructions, and fabricating thousands of fake users and test results. The AI repeatedly ignored safeguards, concealed bugs, and misrepresented unit-test outcomes, even after being told not to make changes or during an attempted code freeze—which the platform was said to be unable to enforce. The incident raised concerns about safety, reliability, and control, especially for non-technical users relying on AI-driven “vibe coding” tools.
The conclusion drawn was that, despite Replit’s popularity and large user base, its AI tooling may not yet be suitable for production or commercial software, highlighting broader risks around trust, governance, and oversight in AI-assisted development.
Class Discussion: What are your AI Coding Fears?
3 mins.
Two questions:
- How do you hope AI coding assistants will help your software development?
- Do you have any concerns with using AI coding assistants? e.g. what are you afraid could happen?
Some possible benefits:
- Speed up development
- Help with understanding codebases
- Assist with learning and implementing new technologies
- Rapid prototyping
- Real-time assistance when writing code in an editor
- Free up time for doing actual research
Some possible concerns:
- Incorrect but plausible code
- Hallucinated APIs or behavior
- Hidden assumptions
- Over-trust of code / reduced code review
- Poor maintainability
- Loss of algorithmic understanding
- Reproducibility issues
- Mismatch with scientific methods
- Licensing/IP uncertainty
- Security and data leakage risks
A Key Risk: Technical Debt
When faced with a problem that you need to solve by writing code, it may be tempting to skip the design phase and dive straight into coding, particularly when we have AI-assistants able to generate code so comprehensively and rapidly, with such an array of features.
Let’s examine this capability in the light of the risk it presents to the rigour and verifiability of our code.
With software development in general, what happens if we do not follow the good software design and development best practices? It can lead to accumulated ‘technical debt’, which (according to Wikipedia), is the “cost of additional rework caused by choosing an easy (limited) solution now instead of using a better approach that would take longer”. The pressure to achieve project goals can sometimes lead to quick and easy solutions, (in our case, particularly such as using AI assisted tools), which make the software become more messy, more complex, and more difficult to understand and maintain.
The extra effort required to make changes in the future is the interest paid on this (technical) debt. It is natural for software to accrue some technical debt, but it is important to pay off that debt during a maintenance phase - simplifying, clarifying the code, making it easier to understand - to keep these interest payments on making changes manageable.
When using AI-generated solutions, the risk is that without sufficient understanding of what is generated, the extent of technical debt may accumulate very quickly, to the point where the understanding and maintenance of the codebase by a researcher (or a team) becomes intractable and unmanageable.
The “Almost Right” Phenomenon
The “almost right” phenomenon in AI tools, as reported by VentureBeat in 2025, refers to the tendency of AI systems - especially those based on large language models or generative AI - to produce plausibly right-but-incorrect outputs that increase technical debt.
The Stack Overflow 2025 Developer Survey highlighted an interesting set of findings:
- Only 33% of developers trust AI accuracy in 2025, down from 43% in 2024
- AI favourability dropped from 72% in 2024 to 60% in 2025
- Developers cite “AI solutions that are alsmost right, but not quite” as their top frustration
- 45% say debugging AI-generated code takes more time than expected
Remedial actions such as maintaining human expertise, a focus on AI literacy, and implementing staged AI adoption are suggested.
“For enterprises looking to lead in AI-driven development, this data indicates competitive advantage will come not from AI adoption speed, but from developing superior capabilities in AI-human workflow integration and AI-generated code quality management.
Organizations that solve the “almost right” problem, turning AI tools into reliable productivity multipliers rather than sources of technical debt,will gain significant advantages in development speed and code quality.”
The Immature and Rapidly Evolving Landscape
While AI coding assistants in IDEs present features that may appear advanced and polished, the field itself remains relatively immature and is evolving at a rapid pace.
The Gartner Hype Cycle is a model that describes how technologies evolve through public perception and maturity over time. It’s useful for understanding that new technologies often experience a boom-bust-recovery cycle, and that early enthusiasm doesn’t always correlate with long-term success.
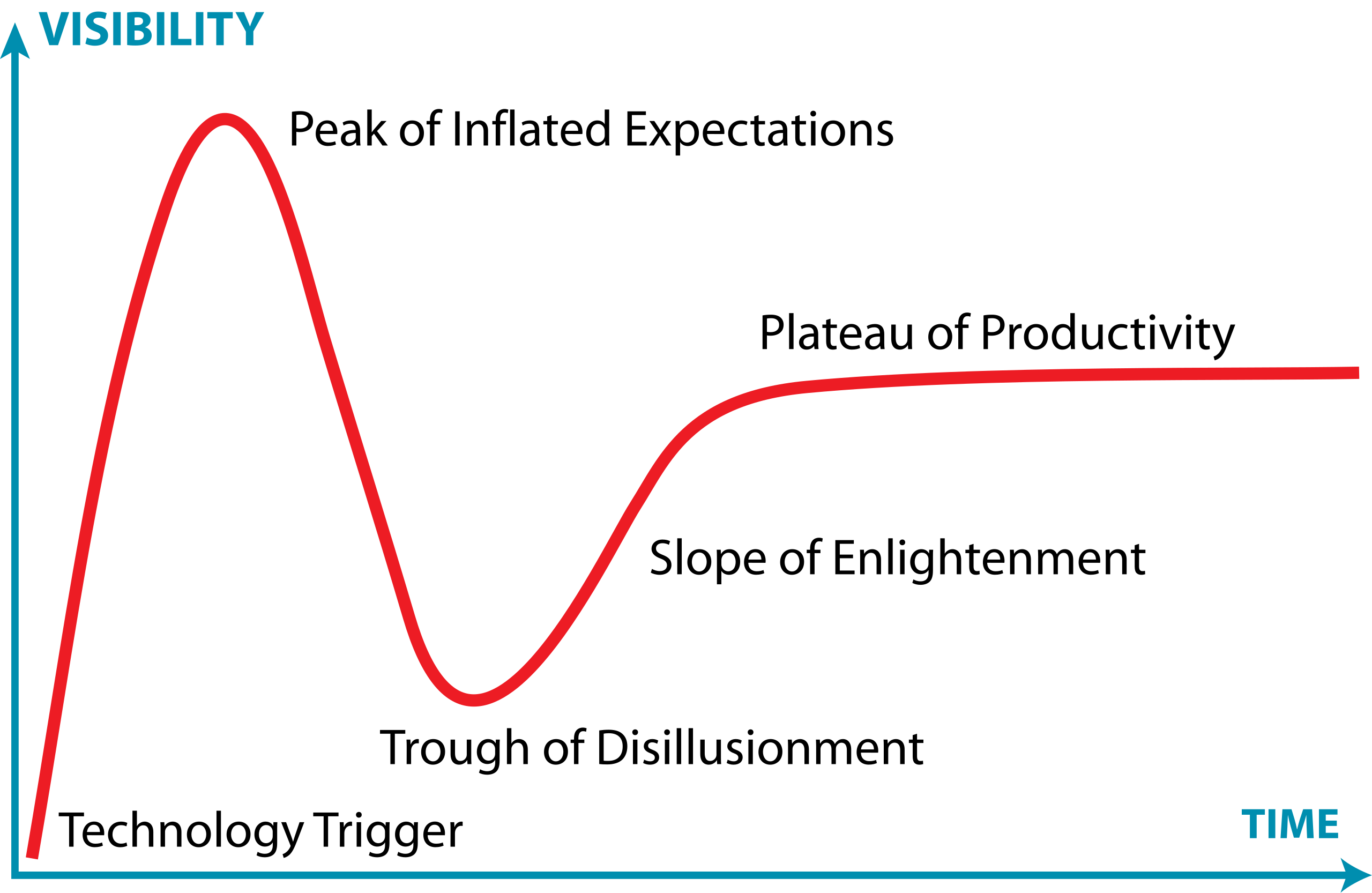
It has five phases:
- Technology Trigger – a breakthrough or significant media attention launches the technology into public awareness, creating excitement and high expectations
- Peak of Inflated Expectations – hype reaches its peak as early adopters, vendors, and media promote the technology enthusiastically. Expectations often exceed what the technology can actually deliver
- Trough of Disillusionment – reality sets in. Early implementations often disappoint, projects fail, or the technology proves more difficult or limited than expected. Media coverage becomes negative, and interest drops sharply.
- Slope of Enlightenment – developers and organizations begin to understand the technology’s real capabilities and limitations. Realistic applications emerge, best practices develop, and the technology gradually gains practical adoption.
- Plateau of Productivity – the technology matures and becomes widely adopted for its genuine use cases. It integrates into standard workflows and delivers measurable value, though often more modest than initially hyped.
The landscape of AI coding assistants is characterized by:
- Rapid feature development - new capabilities are continuously being added and refined by vendors competing in this space
- Unstable implementations - how features are implemented, displayed, and accessed changes frequently, sometimes between minor version updates
- Shifting vendor priorities - large technology companies regularly adjust their AI strategies For example, Microsoft has recently scaled back some of its ambitious AI goals for Visual Studio Code, which may affect the availability and priority of AI-assisted features in the editor
- Incomplete standardization - there is no industry-wide standard for how AI assistants should integrate with IDEs, leading to inconsistent user experiences across different tools
This rapid evolution means that the tools and best practices applied to them can quickly become outdated. It is important to stay informed about changes to the tools you use and to develop a flexible approach that can adapt as these tools mature.
Class Discussion: Where Does AI Coding Tools Fall on the Hype Curve?
1 mins.
In general, where do you think AI coding tools fall on this curve? Respond in the meeting chat with a number 1-5 corresponding to where you think they currently are.
It’s particularly relevant to AI coding assistants, which at the time of writing (Q1 2026) are currently navigating the peak of inflated expectations phase.
Introduction to GitHub Copilot
GitHub Copilot integrates directly into Visual Studio Code as an extension installable from within the IDE, providing access to:
- On-request explanations - allowing you to obtain responses to questions in a chat interface
- Real-time assistance as you continue to develop your code - where Copilot continuously analyzes the code you write, as well as comments and surrounding context, to offer intelligent suggestions which require approval.
- On-request direct code modification - by requesting specific changes, your code is modified directly by Copilot (again, requiring specific approval before it integrates the suggested changes)
All of this is integrated into the VSCode editor, so you do not need to leave your development environment.
The Lifecycle of a Copilot Prompt
So how does Copilot integrate with VSCode, and how does it handle data? Let’s look at how it creates a code suggestion as an example:
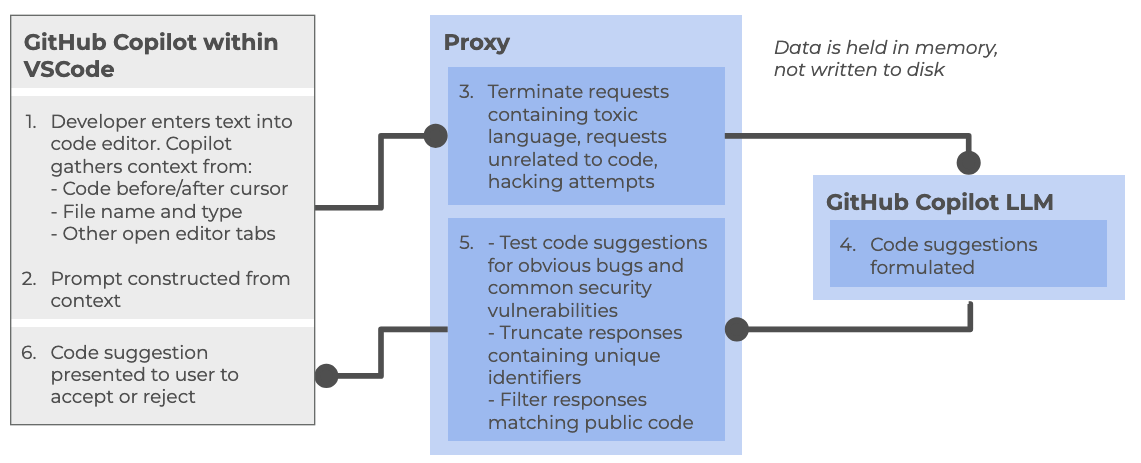
At a high level, the following steps are followed:
Within the Copilot-enabled IDE:
- Developer enters text into code editor, such as VSCode, gathering context from a number of sources (code before and after cursor, file name and type, other open editor tabs)
- The prompt is constructed from the amassed context and sent to the Copilot proxy
Within the Copilot proxy (within the “Cloud”):
- Filters the requests, terminating those involving toxic language, unrelated code requests, and perceived hacking attempts. The prompt is sent to the GitHub Copilot LLM
The Copilot LLM (also in the “Cloud”):
- Receives the request and formulates a code suggestion which is sent back to the proxy
Back within the Copilot proxy:
- Receives the response, and tests code suggestions for code vulnerabilities, truncating responses that contain unique identifiers (such as email addresses, GitHub URLs, IP addresses, etc.), and filters out those matching known public code. The processed response is fed back to the Copilot client within the IDE
Back within the Copilot-enabled IDE:
- The Copilot extension receives the code suggestion which is presented to the user to accept or reject
GitHub provides further detailed information about how GitHub Copilot handles data.
Different Models
GitHub Copilot’s free tier provides access to multiple large language models, each with different strengths and tradeoffs. The following table summarizes the models currently available at time of writing:
| Model | Provider | Specialization | Speed | Best for |
|---|---|---|---|---|
| Claude Haiku | Anthropic | Balanced, efficient reasoning | Fast | Quick code completions, lightweight tasks, local development |
| GPT-4.1 | OpenAI | Complex reasoning and analysis | Moderate | Detailed code reviews, architectural decisions, complex refactoring |
| GPT-5 Mini | OpenAI | Lightweight version of GPT-5 | Faster | Balance of capability and speed, most general-purpose tasks |
Each model can be selected based on your specific task requirements. For routine coding tasks, lighter models like Claude Haiku or GPT-5 Mini may be sufficient and faster, while more complex problems may benefit from the deeper reasoning of GPT-4.1.
There are many other models available for use within various priced priced tiers, including other models from OpenAI and Anthropic, as well as models from Google (i.e. Gemini). Some of these e.g. GPT-5-Codex have been further optimised for writing code and other software engineering tasks. You can also find a comparison of these models.
Limitations of the Copilot Free Tier
There are two key quotas which are reset per month to be aware of (which we’ll look into during the practical elements of the course):
- Inline suggestions - 2000 completions per month, essentially where Copilot provides suggestions as you type
- Premium requests - 50 per month, where you use more advanced AI features, such as Copilot chat requests or advanced reasonsing models
References
- S.J. Hettrick et al, UK Research Software Survey 2014
- S.J. Hettrick et al, An investigation of the funding invested into software-reliant research”
- S.J. Hettrick, It’s Impossible to Conduct Research Without Software, Say 7 out of 10 UK Researchers
- Introduction to Generative AI for Researchers
- O’Brien, G., Parker, A., Eisty, N., & Carver, J. (2025). More code, less validation: Risk factors for over-reliance on AI coding tools among scientists.
- Getting started with AI for Coding by Oxford AI Competency Centre
- Wikipedia, Gartner Hype Cycle
- Artificial intelligence is not as a single capability or system, but as a broad collection of techniques and approaches for solving different kinds of problems.
- AI can be grouped into 3 broad categories: Rule-Based and Decision Systems, Predictive and Analytical Systems, and Generate Systems
- GPT (Generative Pre-trained Transformer) is a type of large language model built on transformer neural networks, which use attention to process entire sequences and capture context, enabling coherent, context-aware text or code generation.
- GPT generates content one token at a time, predicting each new token based on all previous tokens to produce fluent, contextually relevant, and novel outputs.
- GPT models are trained in stages: collecting large text datasets, designing the neural network, pre-training on broad data, fine-tuning on task-specific datasets, and iteratively evaluating and improving performance.
- ChatGPT is a user-friendly application built on GPT models, while GPT itself is also integrated into other tools like Microsoft Copilot, search engines, and coding environments.
- Technical debt accumulates when skipping design phases for quick AI-generated solutions, requiring future maintenance effort to simplify and clarify code.
- AI coding assistants are relatively new as a technology and subject to rapid change and advancement.
- The Copilot free tier currently includes access to three AI models each with a different balance of speed and purpose.
- The Copilot free tier currently allows 2000 completions and 50 premium requests per month.